Prompt-to-Prompt Image Editing
with Cross Attention Control
TL;DR
将文本驱动的图像合成拓展到文本驱动的图像编辑是很自然的。这个方向面临的挑战是:编辑任务通常是保留未编辑的部分,保留大部分的原始图像。然而在基于文本驱动的模型中,即使是对文本本身进行微小的改动,也会导致截然不同的结果。在本文之前的STOA方法用mask来缓解这个现象,但也忽略了Mask中间的信息。本文追求一种直观的prompt-to-prompt 仅有文本控制的图像编辑框架。经过研究发现 —— cross attention layer是控制图像空间分布和prompt 中每个单词的关键,基于这个观察,作者提出了几个应用程序,通过仅编辑文本提示来监控图像综合。这包括通过替换一个词进行局部编辑,通过添加说明进行全局编辑,甚至精细地控制一个词在图像中的反映程度

Method

- key observation: 生成图像的外观和结构不仅依赖于random seed, 也和 在diffusion过程中图像pixel 和 text embed 之间的关联
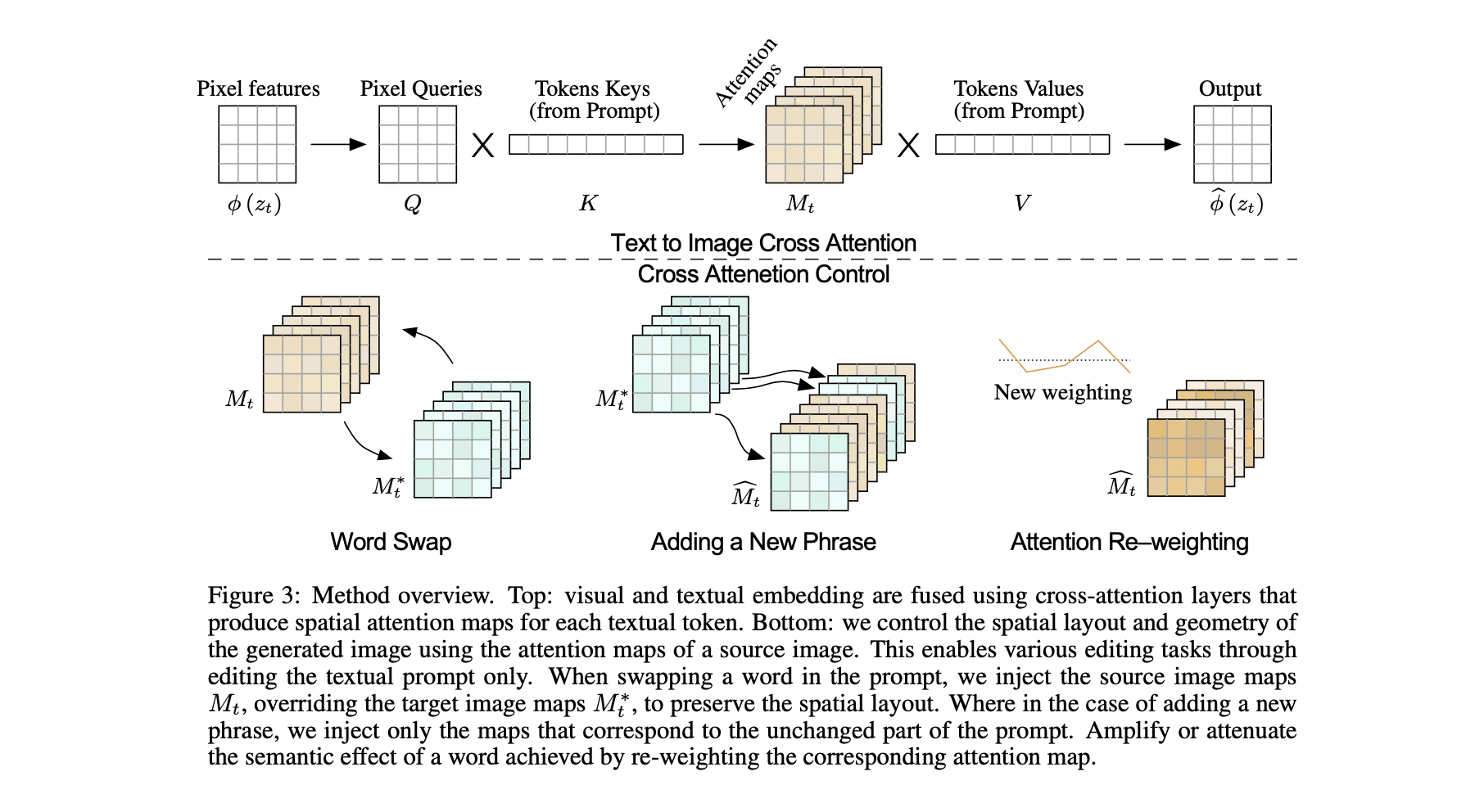
Cross attention in text-conditioned Diffusion Models
- 使用ImageGen —— text-guided 合成模型作为backbone,只在text-to-image的扩散过程进行适应,原有的SR过程保持不变
- noisy image $\phi(zt)$ 被映射成 Query matrix $Q = l_Q(\phi(zt))$. textual embedding 被映射为 key matrix: $K = l_K(\phi(P ))$, value matrix $V = l_v(\phi(P))$。attention mask 如下, mask 用于衡量Q K之间的相似度,为了增加表达能力,并行也使用了multi-head attention.
$$
M = Softmax(\frac{QK^T}{\sqrt{d}})
$$Controlling the Cross-attention
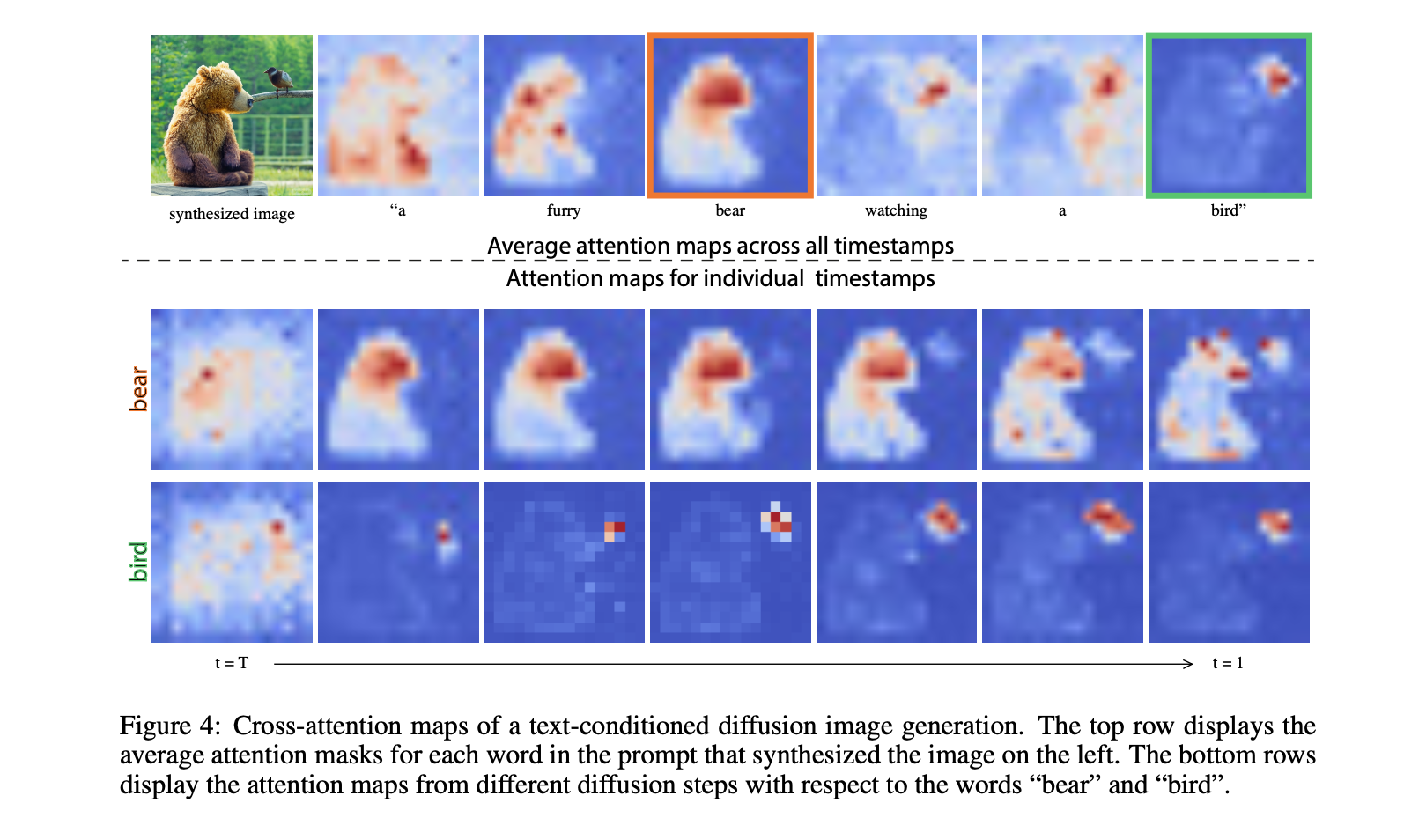
生成的图像的空间布局和几何形状依赖于跨注意力图。 可以看出注意力mask 随着关键词汇变换的过程,而且在早期,注意力mask 已经具有雏形。由于注意力反映了整体的组成,我们可以将从原始提示 P 的生成中获得的注意力图 M 注入到修改后的提示 P* 的第二次生成中。这允许生成一个编辑后的图像 I*,该图像不仅根据编辑后的提示进行了操控,而且还保留了输入图像 I 的结构。
- **
DM(zt,P,t,s)**:这是一个扩散过程的单步计算,其输出是噪声图像zt−1和注意力图Mt(如果没有使用则省略)。 - **
DM(zt,P,t,s){M ← M∗}**:这是我们使用额外给定的图M∗来覆盖注意力图M的扩散步骤,但保持来自提供的提示的值 **V∗**。 - **
Mt***:这是使用编辑提示P*产生的注意力图。 - **
Edit(Mt, Mt*, t)**:这是一个通用的编辑函数,它接收原始和编辑图像在生成过程中的第t个注意力图作为输入。

- **
Edition 函数的定义
- word swap
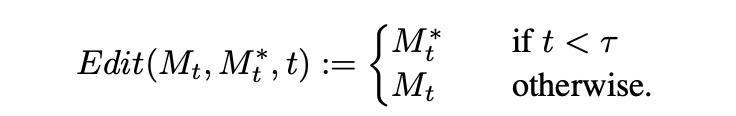
- Adding a new phrase 。P =“a castle next to a river” to P∗ =“children drawing of a castle next to a river”
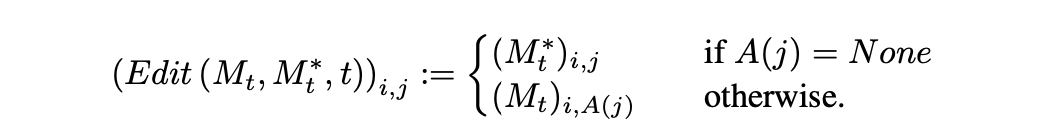
- Attention re-weighting: P = “a fluffy red ball” 例如改变材质的程度
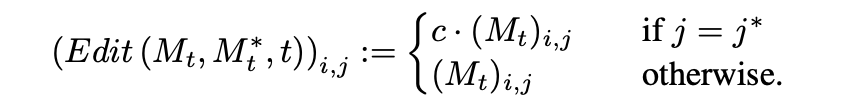
Application
文章介绍了一些应用,包括
- Text-Only Localized Editing.

- Global editing.

- Fader Control using Attention Re-weighting.
