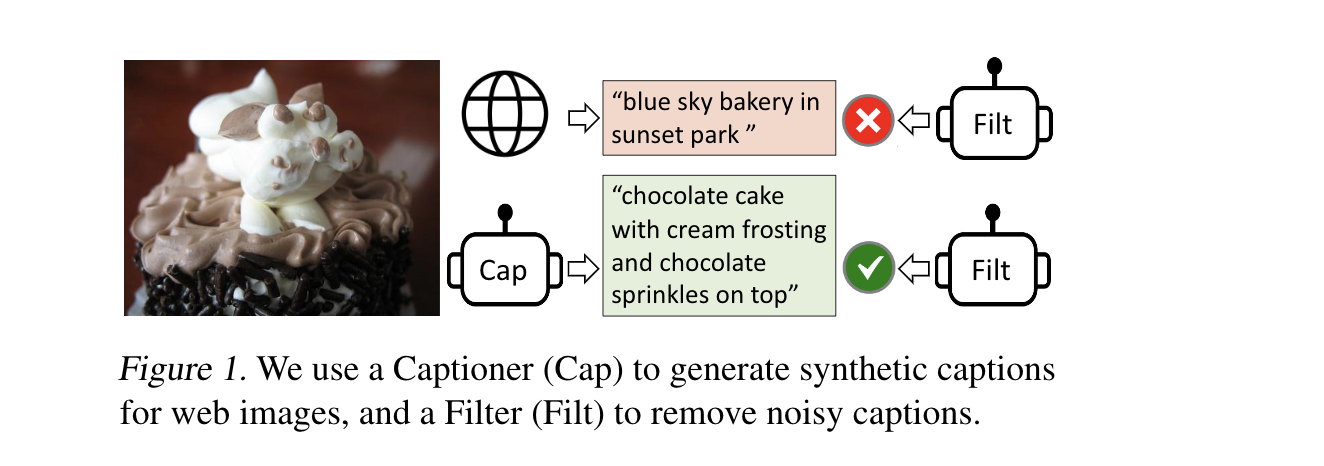
TL;DR
VLP(vision-language pretraining),现有的预训练模型在内容理解类任务或者生成类任务上仅能做好两者之一,无法同时兼顾。随着scaling up noisy 的文本-图像对数据集,该任务取得了巨大的进步。BLIP采用 bootstraping caption的方法来利用充满噪声的网络数据,该captioner 会生成合成的字幕并且将带噪的字幕做一次过滤。BLIP方法在图文搜索,图像打字幕以及视觉问答上都取得了巨大的进步。
Method
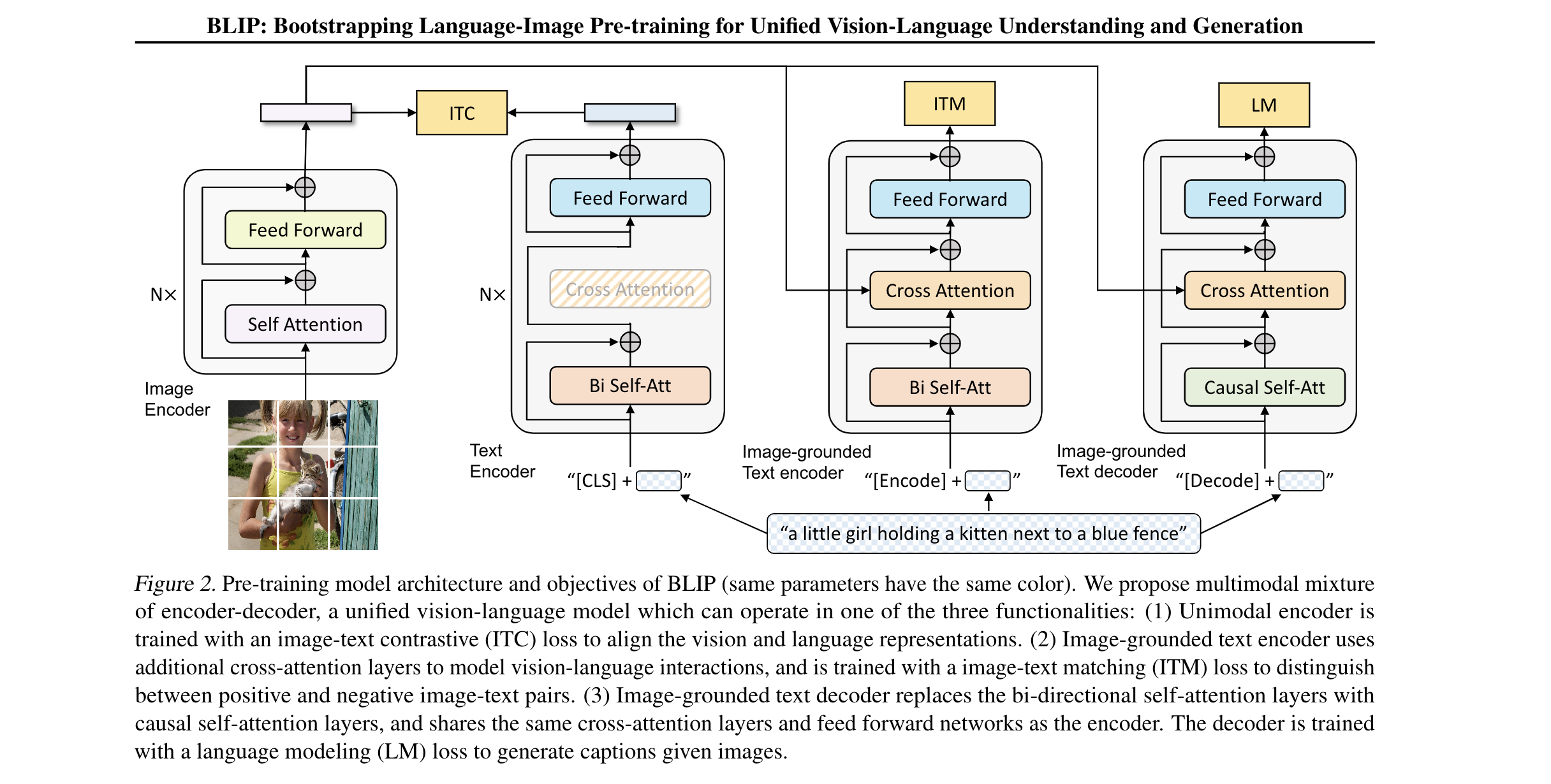
- BLIP,预训练模型的结构使用了多模态混合的 encoder-decoder结构,一种固定的VL模型,可以处理三种之一的功能。(1)单模态的编码器通过ITC loss 训练,作用是对齐视觉和文本的表征 (2)Image-grounded 文字编码器使用额外的跨注意力层来建模视频语言的交互,训练中使用image-text matching (ITM loss) 来区分图文对中的正样本和负样本。(3)Image grounded 文本解码器使用 causal self-attention layer 替换了双向的 self-attention layer。 同时和encoder使用了相同参数的cross attention / feed forward 。 解码器使用LM (language modeling loss )来生成字幕
- Model Arch:使用Vit 模型作为Image Encoder。先把image 切分成多块patch,并把其编码成一系列的向量,同时带上额外的「CLS」token 来表示完整的图像特征。
- Unimodal encoder: 文本编码器和视觉编码器是独立的。BERT 的text encoder。同时插入在text input 前插入一个「CLS」token。
- Image-grounded text encoder: 在每个text encoder 的transformer 模块中,在self-attention 和 feed-forward 模块中间插入跨注意力层。一个task-specific [encoder] token 被添加到text 当中,它的输出则作为图文对的一种多模态表示
- Image-grounded text decoder: 一个「Decode」token被用开始的信号,end-of-sequence token 用于表示结束的信号。
- Pretraining Objective
- 在预训练阶段,同时优化三个目标函数。其中两个(ITC/ITM)是理解类的目标函数,LM属于生成类的目标函数。从图中可以看出,对于一个图像文本对的样本,它的前向需要经过一个计算量大的VIT网络,同时也要通过三次文本编码器。
- ITC:原理是鼓励正样本有相似的相似的表征,而负样本则尽可能的不同。ITC loss 使用了带momentum 的编码器来生成特征。同时使用编码器来生成软标签,从而从负样本中找到正样本
- ITM:主要作用在Image-grounded text encoder 上,能够生成图文多模态表征。ITM是二分类任务,模型使用ITM Head(linear)来预测图文是否匹配。为了使得从负样本中挖掘更多信息,使用了负样本挖掘技术,具体来说就是用相似度较高的负样本来计算loss
- LM:cross entropy loss 。在计算loss使用了0.1 权重的label smoothing
- 利用多任务学习的特性,所有文本编码器中的自注意力层参数都是共享的。对于current input token, 文本编码器使用双向注意力层来建立编码表示。对于解码器,使用causal 自注意力层来预测下一个token。
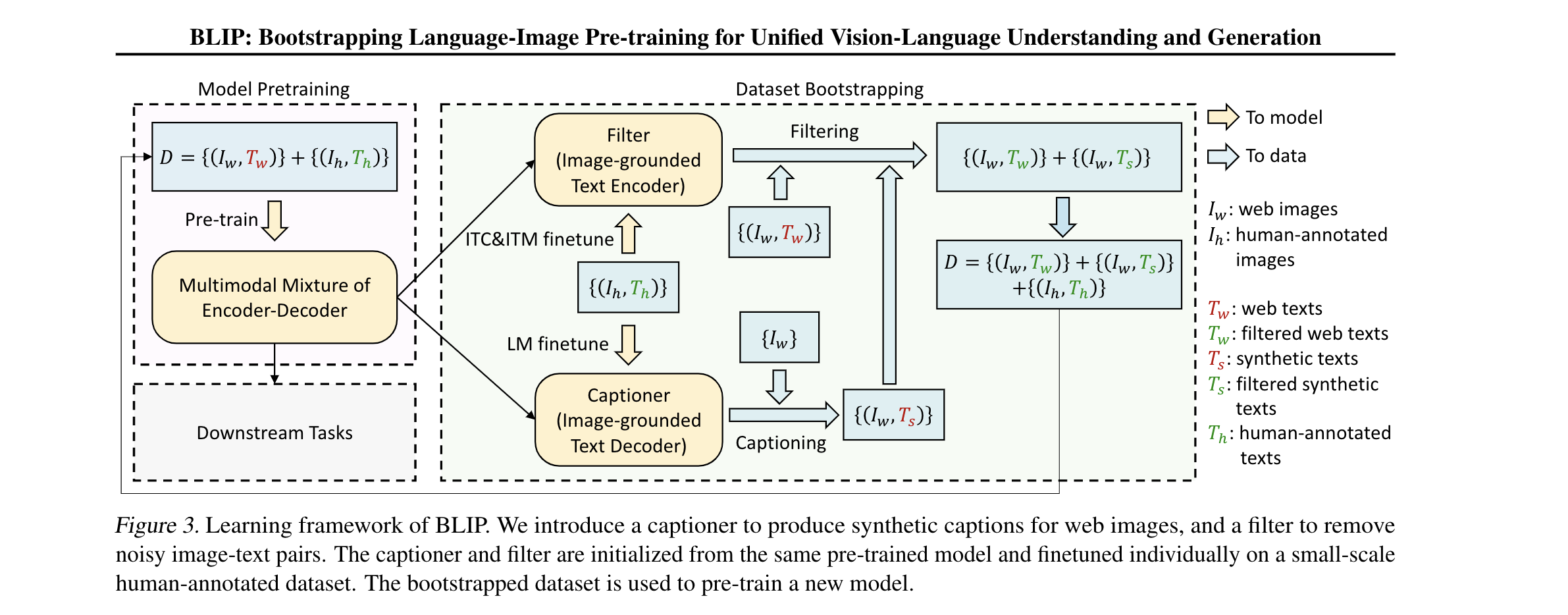
- CapFilt
- 由于标注成本的问题,高质量的标注图文数据记为${(I_h, T_h)}$,典型数据就是COCO。和网络上搜集到巨量文本对,${(I_w, T_w)}$。主要包括:一个输入web 数据, 生成caption的captioner .一个能够筛选过滤 noisy 数据的filter。这两部分的模型权重都由MED预训练权重得到。
- captioner 的结构和image -grounded text decoder 一致,使用LM目标函数来进行finetune. 对 $I_w$ 进行打字幕得到文本合成描述 $T_s$。用ITC ITM来训练fliter, 过滤器过滤掉了$T_s, T_w$。最终得到一个新的完整数据集
Experiment
Pretraining Details
- 图像编码器的预训练模型是在Imagenet上训练得到的,文本编码器的预训练模型由BERT来初始化。本文探索了两种配置 Vit-B / Vit-L. pretrain 时用了20个epoch,其中2880 bs for Vit-B / 2400 for Vit-L. Learning rate 采用warmup的策略,3e-4/2e-4 for Vit-B/ Vit-L . pretrain 时候使用224x224的图像,finetune时候使用384. 训练数据如下图所示:
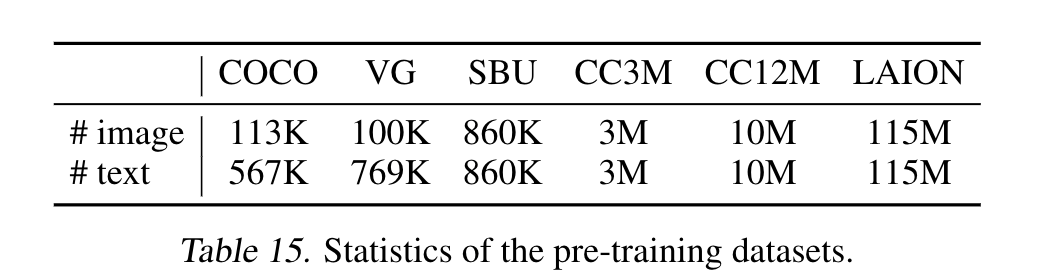
- 图像编码器的预训练模型是在Imagenet上训练得到的,文本编码器的预训练模型由BERT来初始化。本文探索了两种配置 Vit-B / Vit-L. pretrain 时用了20个epoch,其中2880 bs for Vit-B / 2400 for Vit-L. Learning rate 采用warmup的策略,3e-4/2e-4 for Vit-B/ Vit-L . pretrain 时候使用224x224的图像,finetune时候使用384. 训练数据如下图所示:
Effect of Capfilt
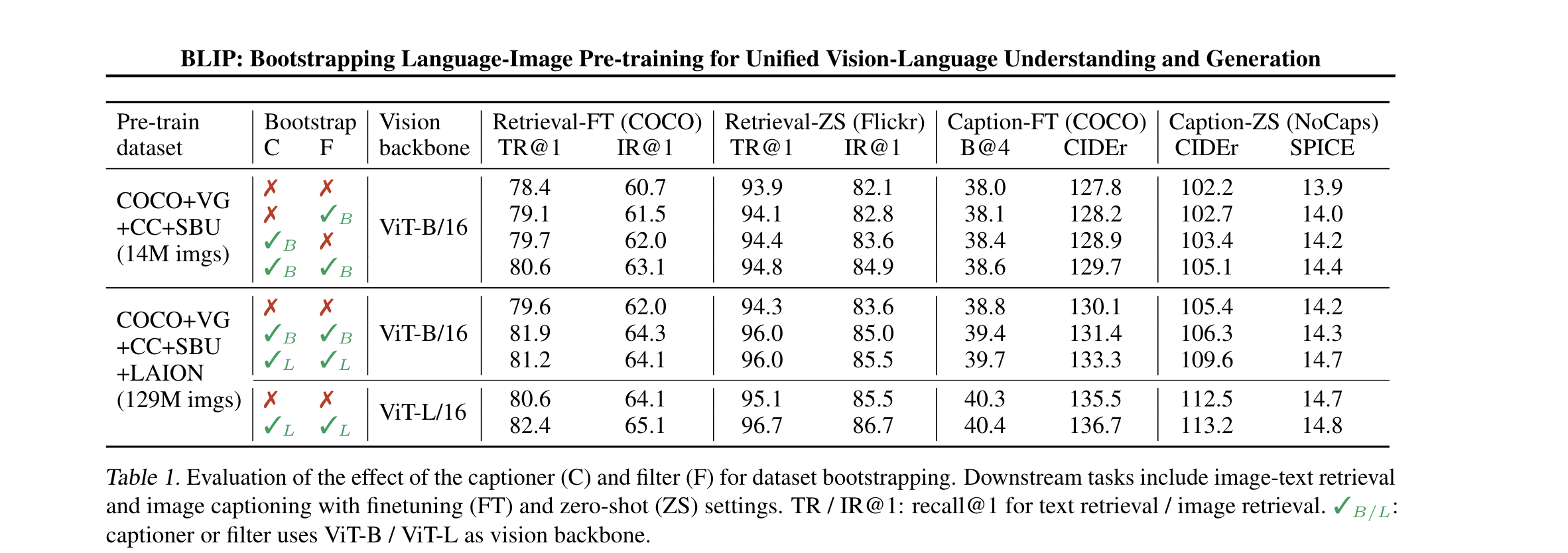
- 作者在两个不同量级的数据集进行了比较,在检索 / caption 任务上都证明了有效性。当caption 和filter相互搭配之后,效果能够进一步提升。并且随着scaling up 数据集和模型大小,都能继续涨点。
- 图中可以看出,captioner 以及 filter的作用

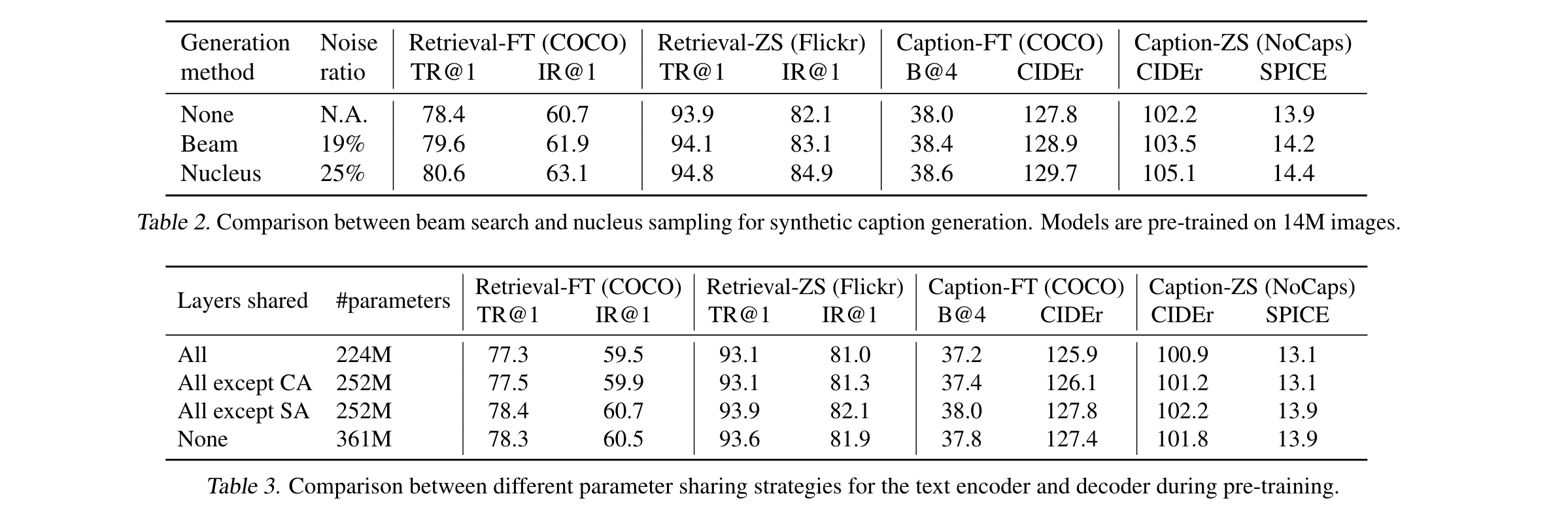
diversity is key for synthetic captions
- 使用nucleus sampling 来生成合成的字幕,作者的解释是因为产生了更加多样性的caption ,尽管noise ratio更高,也能在检索,caption任务上涨点。相比之下beam 生成的caption更加普通,就难以从中获取更多的知识
Parameter Sharing and Decoupling
- 除了self-attention 模块,对所有参数进行共享能够取得最好的效果。作者的解释是,如果self-attention 也是共享的,encoder decoder的冲突将会导致性能的下降

- 在CapFilt中,对图像标注生成器(captioner)和过滤器(filter)进行端到端的独立微调(finetune)任务,任务是在COCO数据集上进行。参数共享:在Table 4中,研究了在captioner和filter之间共享参数的影响,共享方式与预训练相同。结果显示,共享参数导致下游任务性能下降,主要原因被归因于“confirmation bias”(确认偏差)。确认偏差:由于参数共享,captioner产生的带有噪声的标注不太可能被filter过滤掉,这导致captioner生成的低质量标注在下游任务中被误认为是正确的,从而降低了性能。这也可由更低的噪声比率(8%相比于25%)来表示,即captioner生成的噪声标注在参数共享下被较少过滤掉。
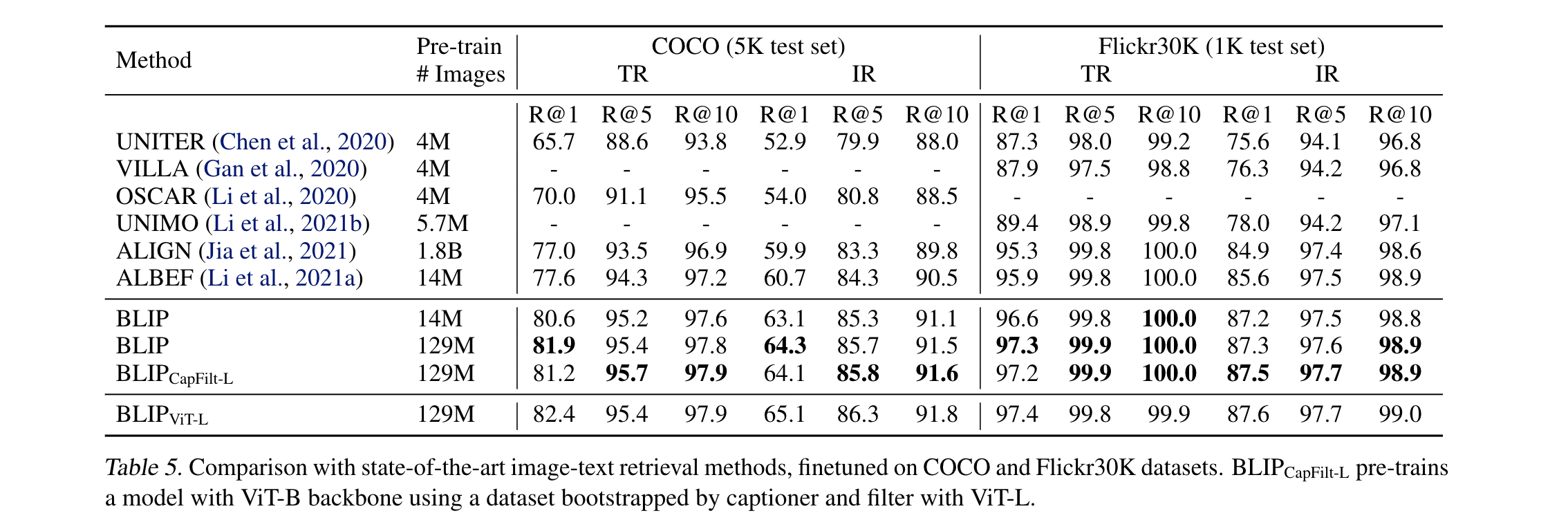
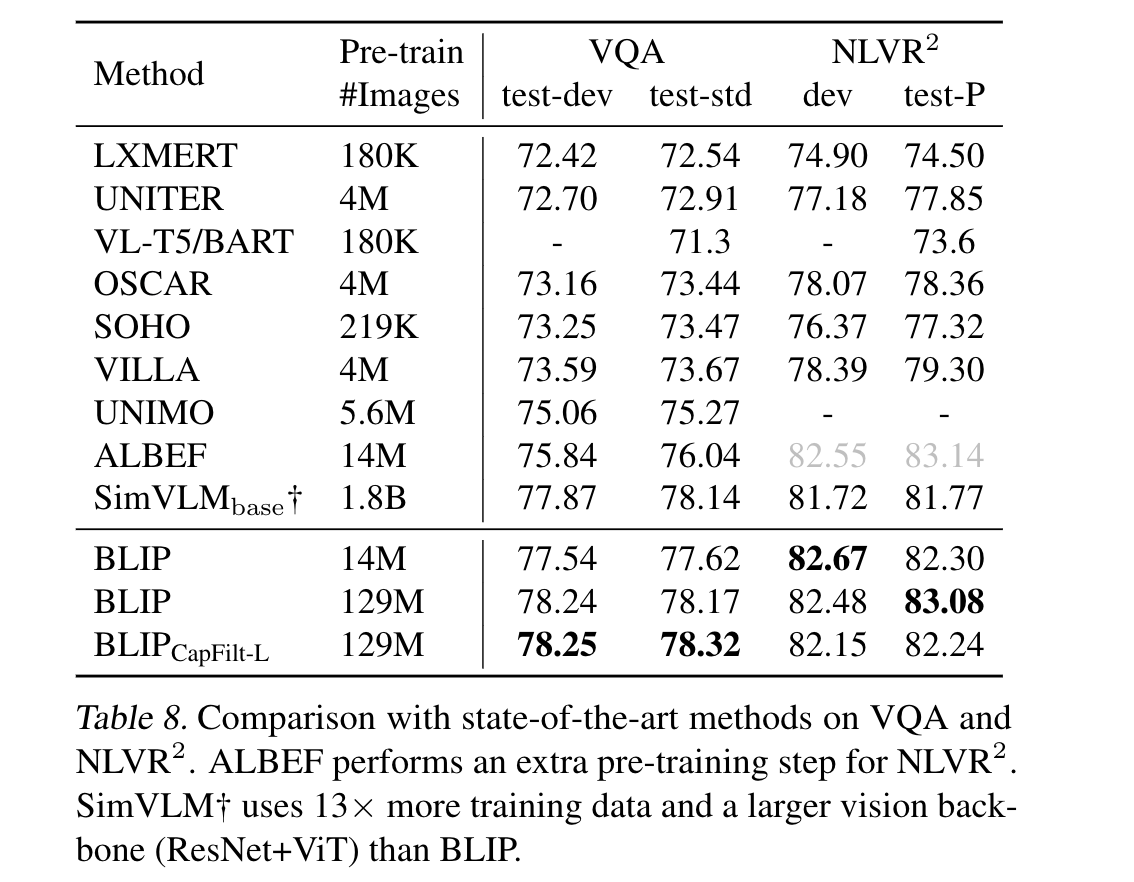
- 在COCO 数据集上,对TR / IR任务进行推理和测试。为了提高推理速度,作者遵循了Li等人(2021a)的方法,首先基于图像与文本特征的相似性选择了k个候选项,然后根据候选项之间的配对ITM得分重新排序。对于COCO数据集,设置k=256,对于Flickr30K数据集,设置k=128。使用14M的pretrain 模型,比先前的ALBEF高了不少。
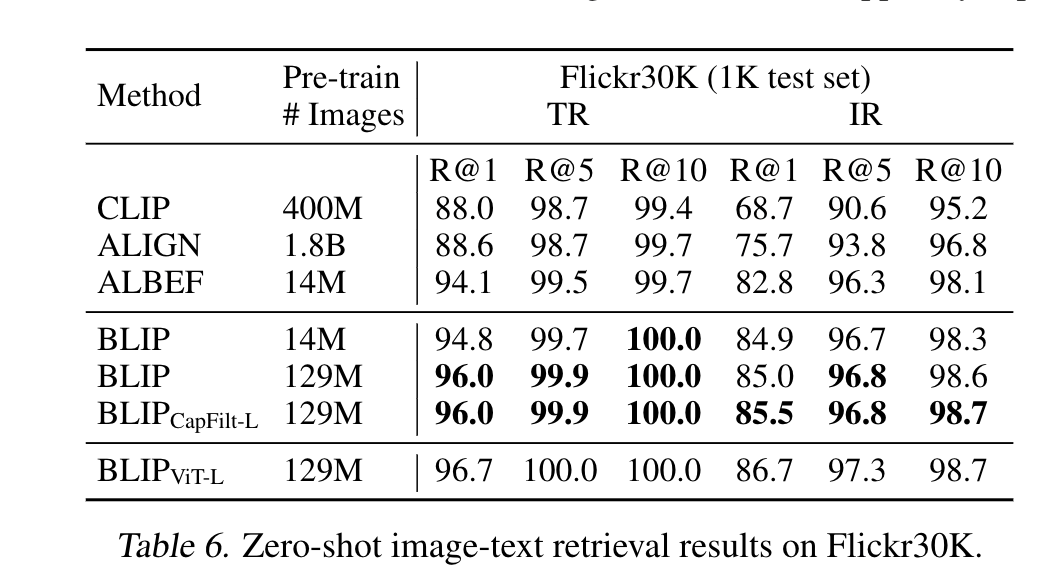
- 测试了一下zero shot, 即在COCO上finetune, 再放到Flicker 30K 上面去测试也能获得不错的效果
Image Captioning
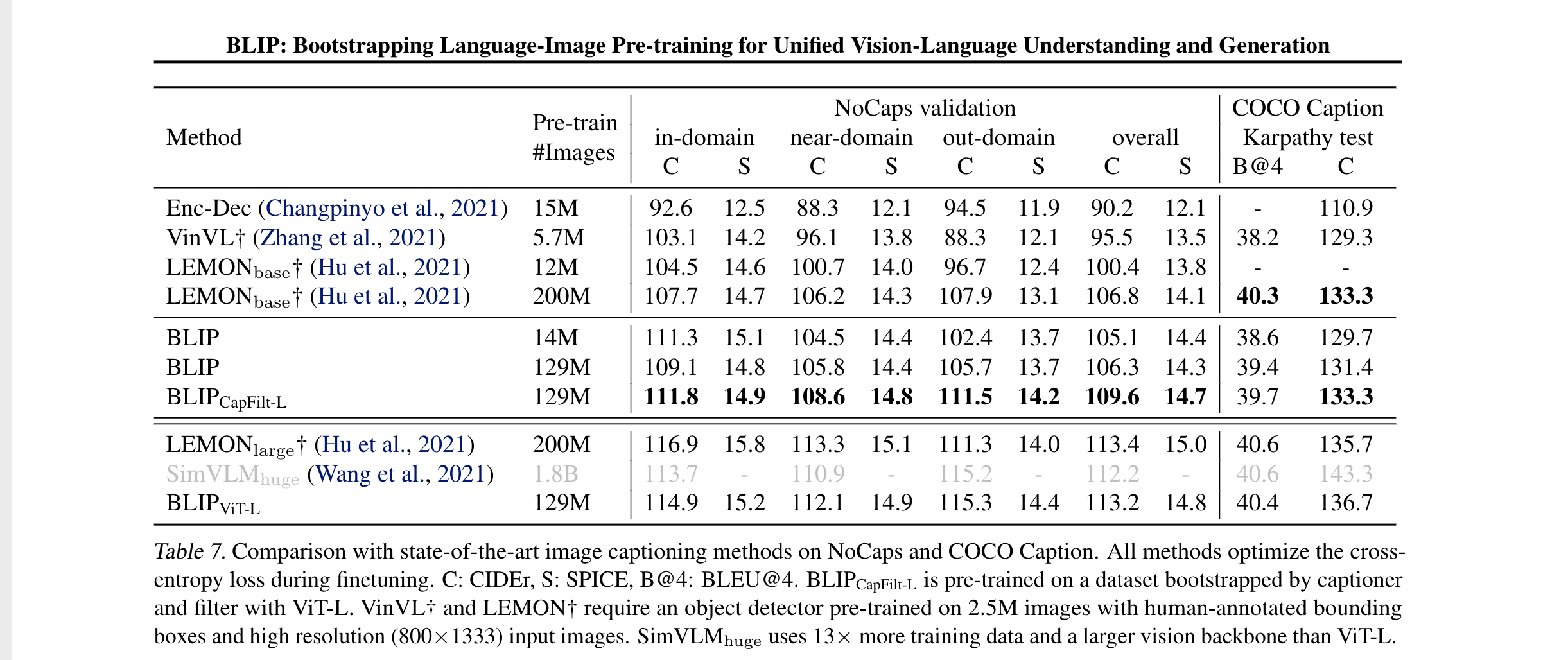
- 每张caption前面都加上 a picture of ,可以提升效果。14M 的BLIP再相同量级的预训练数量上比其他方法要好。LEMON还使用了一个更大的检测器以及更高的分辨率,CLIP不带检测器而且效果也更好
- VQA
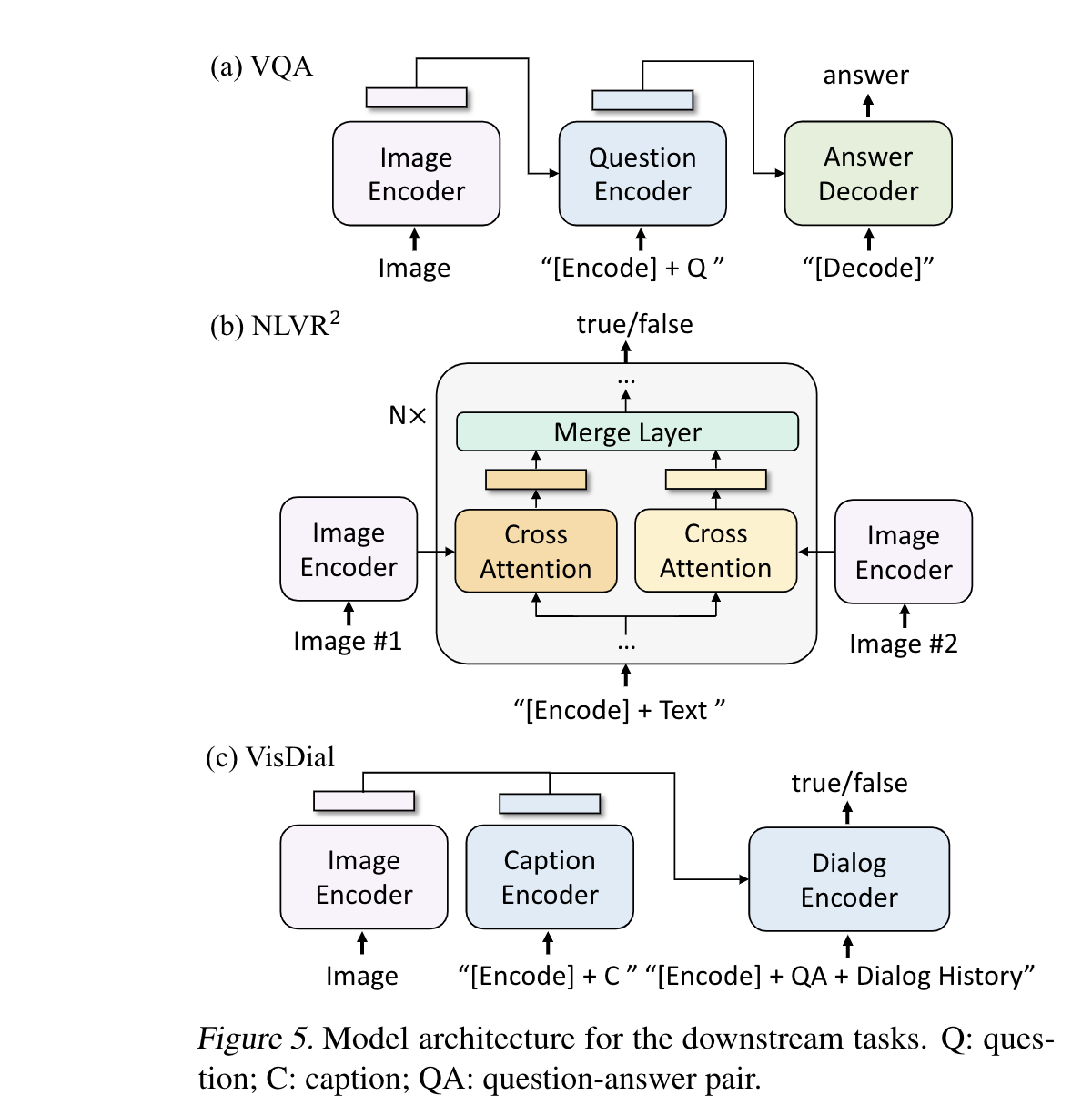
下游任务的模型结构如图所示
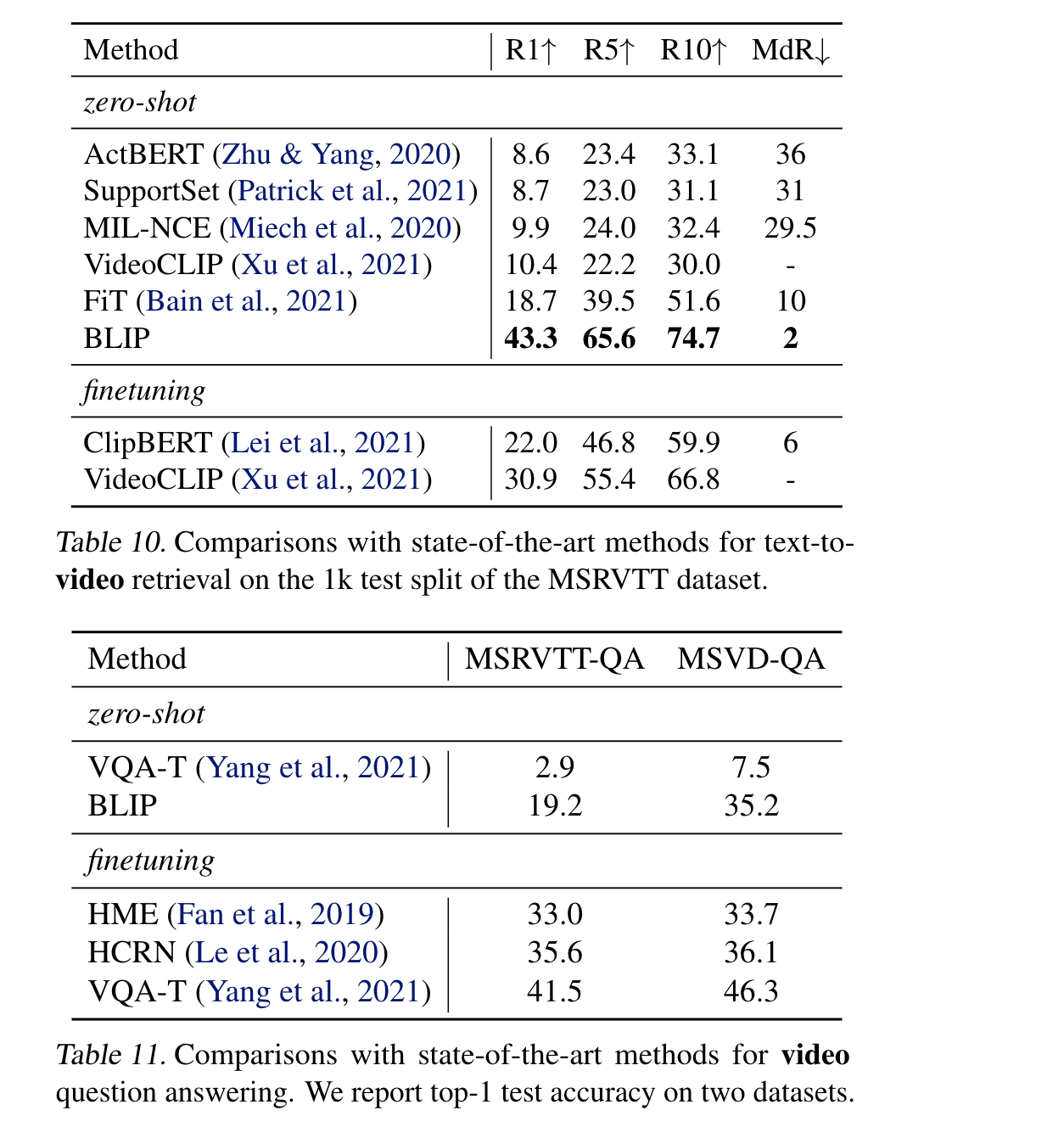
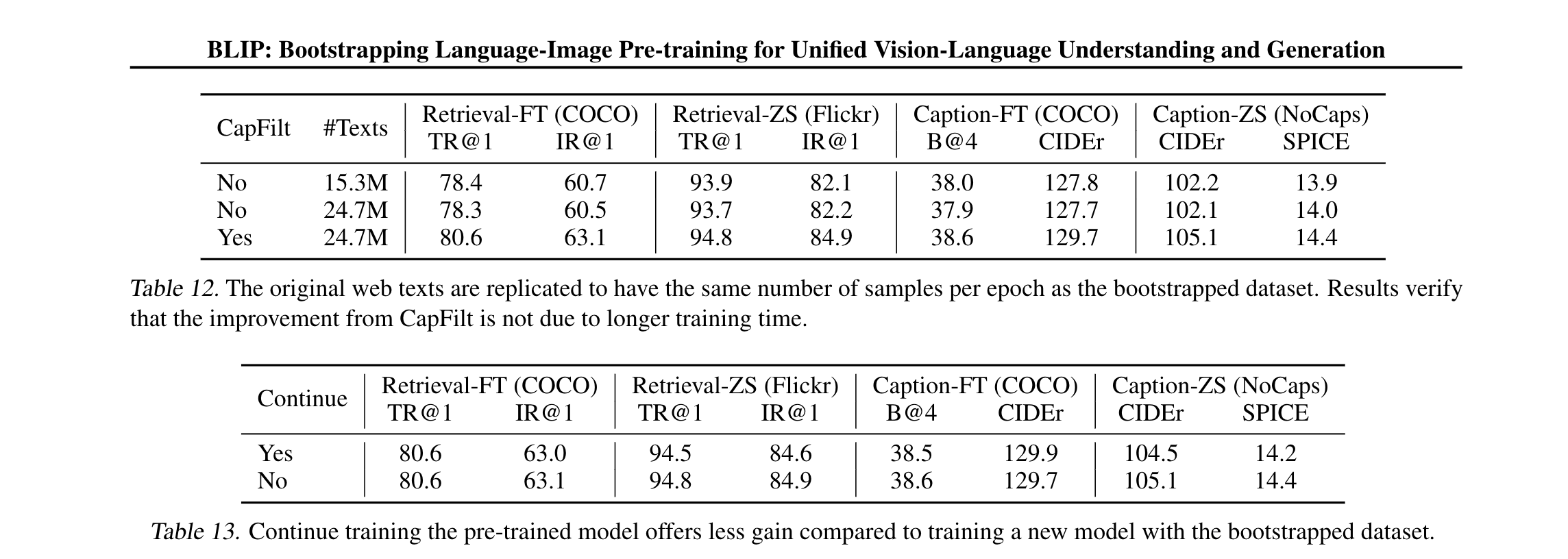
作者还做了一些对比实验,证明了bootstrap 效果提升并不是因为训练时间更长导致的。当bootstrap 的数据拿来预训练一个新数据集时,对原来的pretrained 模型继续训练,效果也没有任何提升了。作者解释说,从知识蒸馏的角度上来看,老师模型不能拿来给学生模型做初始化
Thought
- 多模态任务的预训练,共享了除self attention之外的参数
- bootstrap相当于重新获得了一部分高质量的数据