Segment Anything
TL;DR
在图像分割方面定义了一种新的任务,模型(SAM),数据(SA-1B),该项目搜集了11M 图像和 1B 的mask。该模型在很多任务上完全了评估,展示出比较好的zero-shot性能。

Method
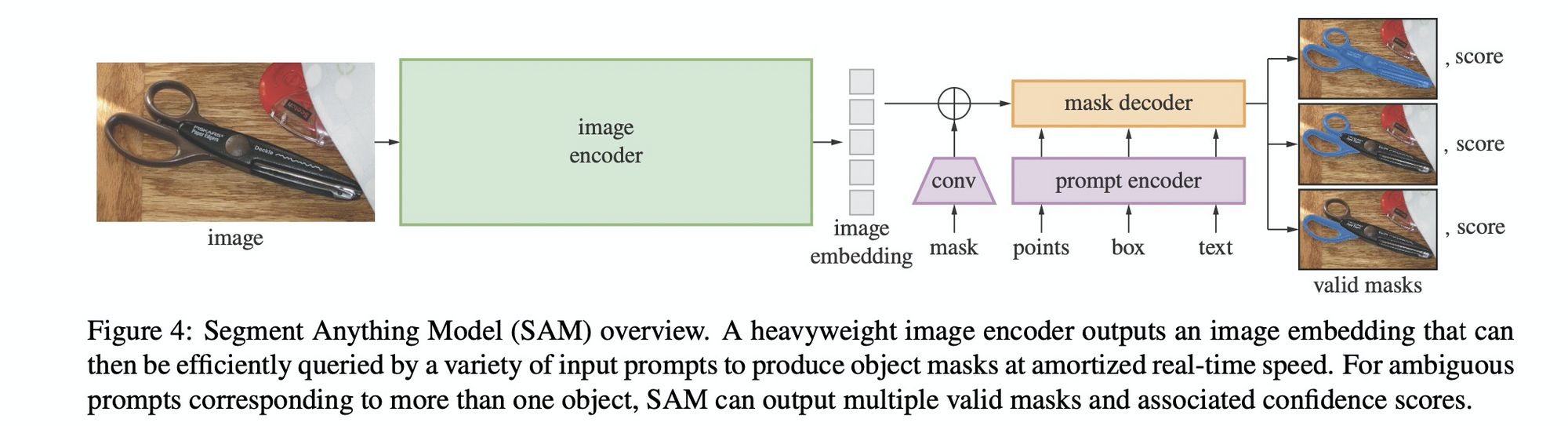
- Segment Anything Model
- 图像编码器:使用MAE预训练的Vision transformer,可以比较好的适配高分辨率的输入。
- 提示编码器:可以是两种类型的提示:稀疏的(point, box, text), 密集的mask。position encoding 表示点和框,加上学习到的该类型的嵌入向量;现成的CLIP编码器来提取文本;mask则用Conv来提取,并和图像的embed做逐元素的相加。
- Mask解码器: decoder 将 image embed 和 prompt embed 和 输出token映射到一个mask。采用的是一种修改版TF decoder模块,后接一个dynamic mask prediction head. 在提示上使用cross attention, self attention 来更新所有embed。过完上述两个模块之后,对图像嵌入进行上采样,然后使用MLP将输出token映射到分类器,该分类器在每个图像位置计算掩模前景概率。
- 消除歧义: 对于有歧义的propmt,模型会平均多个有效的mask。本文的做法是对于同一个prompt,输出3个mask已经足够了。
- 效率: 浏览器CPU上接近50ms,相当于实时的体验
- train & loss: focal loss 和 dice loss 的混合。对于几何上的prompt, 采用了多种形式的混合采样来模拟交互式.
- Segment Anything Data Engine
- data engine: 其实就是标注工具,文中把它分为三个阶段 :
- (1)模型辅助下手工标注:这个阶段在SAM的帮助下,每张图的mask 从 22 增加到44. 标注速度仅比 bounding box 慢一半。
- (2)半自动,即模型自动生成 和 模型辅助下 的混合. 这个阶段标注时间又回到34s, 但是每张图像的mask增加到72
- (3)模型全自动生成 :比较特别的是,在prompt 方面,用了32x32的点来
- data engine: 其实就是标注工具,文中把它分为三个阶段 :
- Segment Anything Dataset
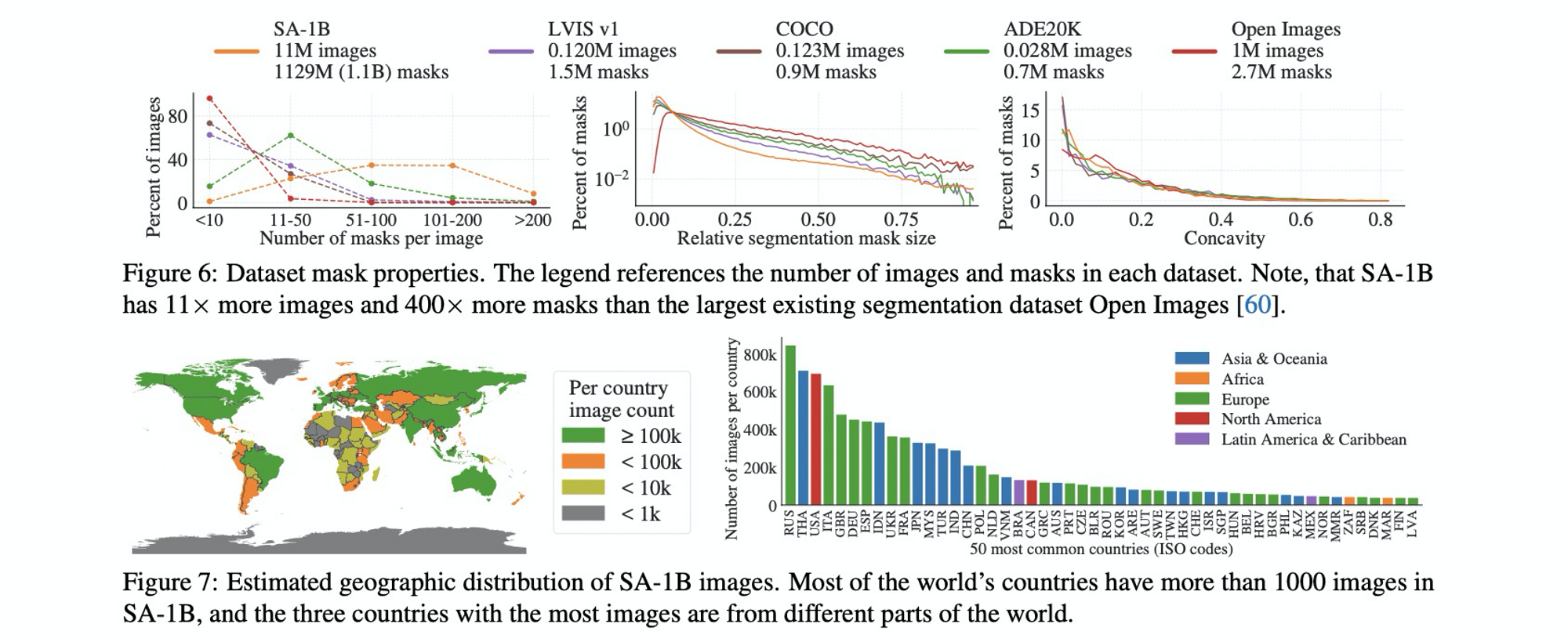
- Images: 获取了一波11M的图像,将最短边缩短到1500,依然比现有数据集分辨率都高
- Mask:1.1B ,mask 质量也很高
Experiment
- Zero-Shot Transfer Experiments
- Zero-Shot Single Point Valid Mask Evaluation
- edge detection
- 对于生成的mask过一个sobel filter,已经能获得质量比较高的edge map
- 物体检测和实例分割表现也很好
- text to mask
- 在训练期间,使用提取的 CLIP 图像embed 作为其第一个输入提示 SAM。由于 CLIP 的图像嵌入经过训练以与其文本embed对齐,因此我们可以使用图像embed进行训练,但使用文本embed进行推理。在推理时可以通过 CLIP 的文本编码器运行文本,然后将生成的文本embed作为提示提供给 SAM