TL;DR
随着模型计算量的增加,Vision-Language 预训练的代价越来越高。本文提出一种高效的VL预训练策略Blip2,可以利用已经训练好的图像模型和语言模型为基础,在此基础上进行新的预训练,从而获得VL的联合表征。
- 提出一种轻量级的Query Transformer, 该模块可以减少视觉和语言之间的gap,该模块通过两阶段预训练构成
- 第一阶段从 frozen的图像编码器中引导 Visual language 的学习。第二阶段从frozen的 language model 中引导vision to language 的生成学习。BLIP2在较少的训练参数情况下,取得了SOTA
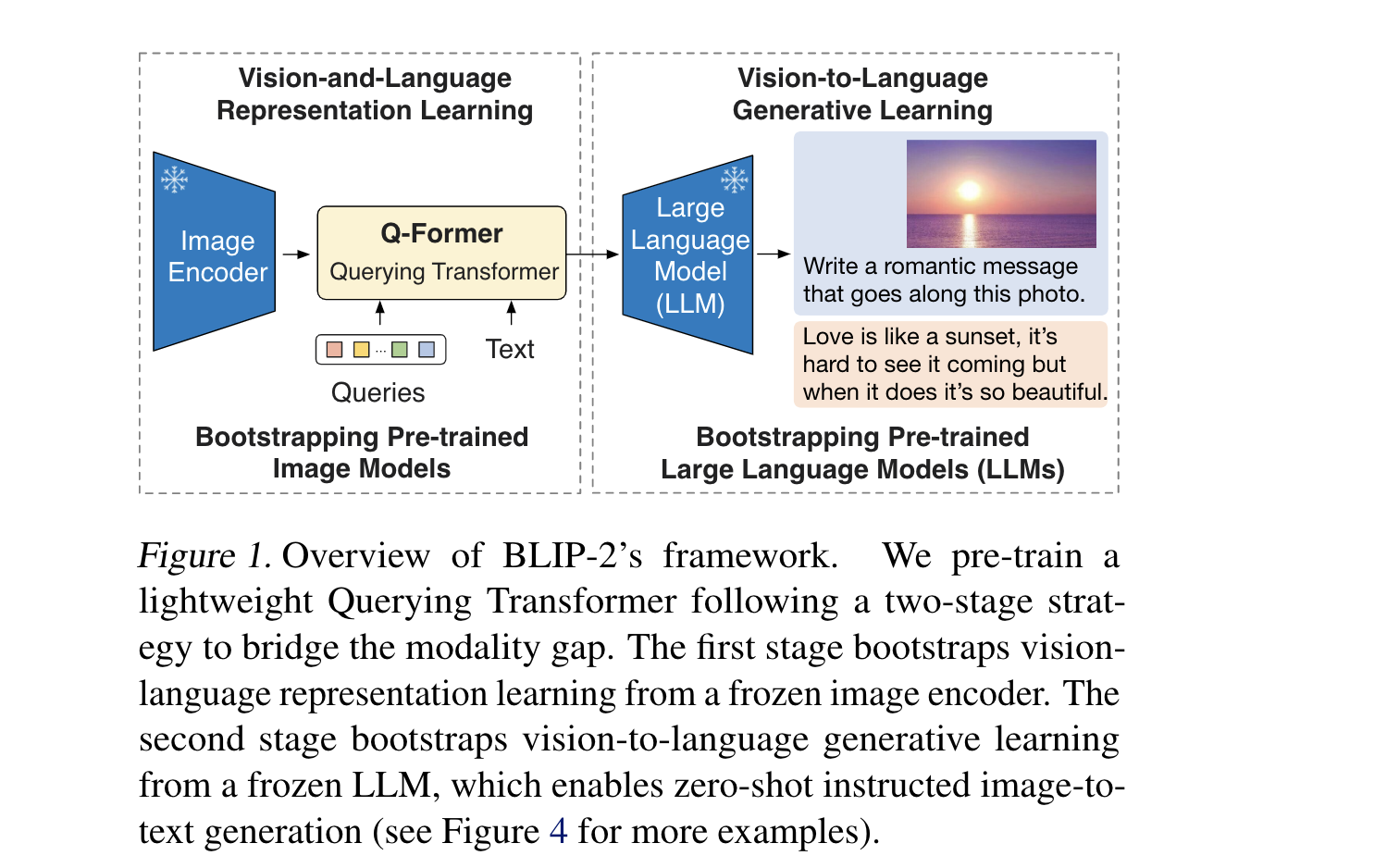
Method
- Model Arch
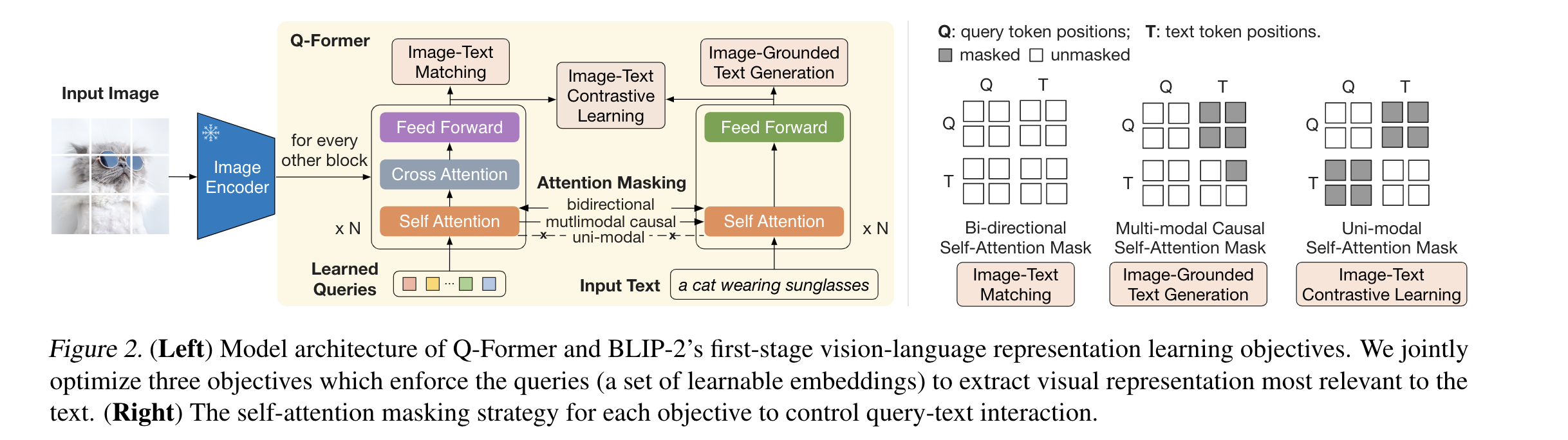
- Left: 表示Q-Former 和 BLIP-2 的一阶段 VL联合表征,这里用上了三个目标函数来使得根据query来提取视觉特征。Right:自注意力掩膜策略,来控制query-text interaction。“查询-文本交互”指的是通过设计查询向量与文本特征的自注意力交互方式,来引导查询向量学习表示与特定文本语义相关的视觉概念。
- Q-Former从图像编码器中提取固定数量的输出特征,与输入图像分辨率无关。Q-Former 一共包括两个transformer 子模块,他们共享自注意力层的参数。(1)一个是图像transformer,它和冻住的图像编码器互相交互,从而提取视觉特征。(2)一个文字transformer,它既可以作为文字编码器,也可以作为文字解码器。
- 创建一组可学习的查询嵌入作为图像transformer的输入。查询之间通过自注意力层交互,通过交叉注意力层与冻结图像特征交互(每两个transformer块插入一个)。查询还可以通过同样的自注意力层与文本交互。
- 对于不同的pretrain任务,使用不同自注意力mask 来实现交互。这里的权重还是用BERT来初始化。
- query (查询向量),在实验中,使用32个长度为768的向量作为query。这个参数远小于图像本身(ViT-L / 14)的特征(257*1024)
- Bootstrap Vision-Language RepresentationLearning from a Frozen Image Encoder
- 将Qformer 和 冻结的image encoder 连接,使用图像-文本对进行预训练,目标是训练Q-former的查询向量,提取和文本最相关的视觉特征。这里会联合优化三个目标,它们们共享相同的输入格式和模型参数。对于每个目标,都使用不同的注意力遮蔽策略来控制「查询向量」和「文本」之间的交互。
- ITC:最大化图像表示和文本表示之间的交互信息,通过正负样本对比学习图像-文本的相似度。unimodal self-attention mask 表示单模态的自注意力遮蔽,查询向量和文本之间不允许相互关注。这样可以帮助它们聚焦在各自的单一模态上,不互相干扰。
- ITG:给定图像作为条件,训练Q-Former 生成对应的文本。作者的解释是,query(查询向量)提取出文本所需要的视觉特征。这里使用多模态因果自注意力遮蔽来控制查询向量和文本之间的交互。“因果遮蔽”(causal masking)指的是只允许attention模块关注到当前位置之前(左侧)的内容,而不能关注到当前位置之后(右侧)的内容。
- ITM:学习图像文本之间细粒度的对齐,判断一个图像文本对是否匹配。查询向量学习多模态信息
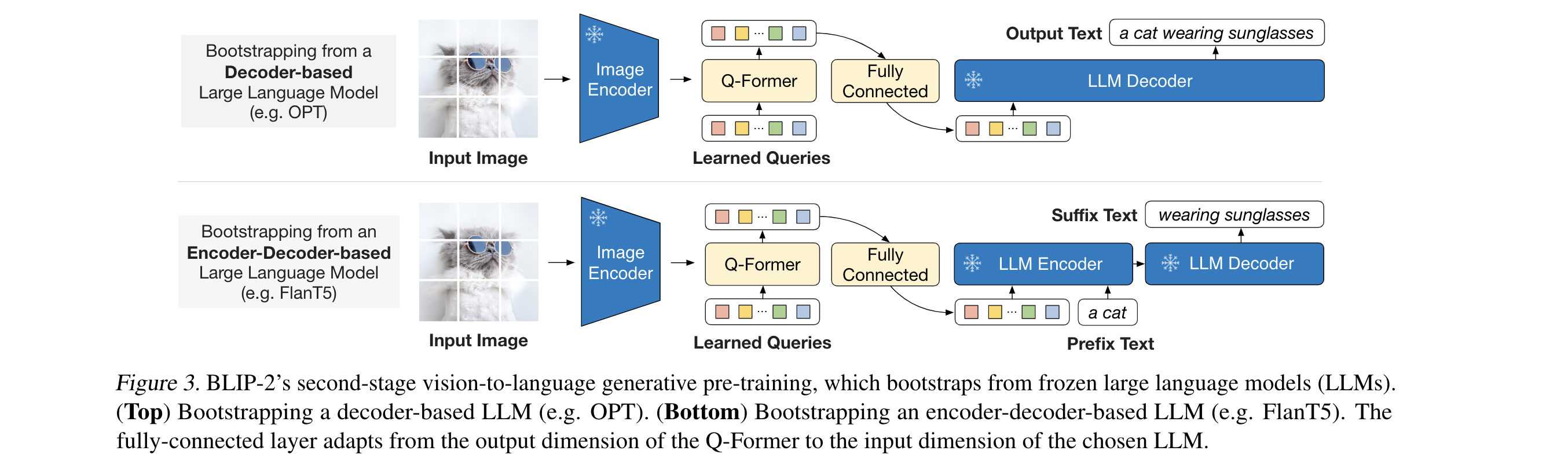
- Bootstrap Vision-language Generative Learning from a frozen LLM
- 在生成的预训练阶段,作者把Q-former和LLM连接,来获得LLM的语言生成能力。如图3所示,这里使用FC来调整Q-former 输出向量到LLM的向量维度。
- 将映射后的查询向量拼接在文本词向量前面,作为软化的视觉提示,为LLM提供相关视觉信息。
- Q-Former通过第一阶段的预训练提取语言相关的视觉表示, 作者的解释是这里能起到信息瓶颈的作用,只向LLM提供有用信息,这样避免了视觉特征和文本特征对齐的难度,避免了遗忘问题。
- 作者对两种LLM做了实验:(1)对于解码器型LLM,使用语言模型损失进行预训练,LLM基于查询向量生成文本。(2)对于编码器-解码器型LLM,使用前缀语言模型损失,将文本拆分成前缀和后缀,前缀与查询向量一起输入编码器,后缀作为解码目标。
- Model Pretraining
- 预训练数据集:总共1.29亿张图像,来源包括COCO、Visual Genome、CC数据集等。使用BLIP的图像字幕模型为web图像生成字幕,保留top2字幕作为训练数据。
- 预训练的图像编码器:探索了CLIP的ViT-L/14和EVA-CLIP的ViT-g/14两种视觉Transformer。去掉最后一层,使用倒数第二层作为输出特征。
- 预训练的语言模型:探索了OPT模型系列的解码器型语言模型,以及FlanT5模型系列的编码器-解码器型语言模型。
- 预训练设置:第一阶段预训练25万步,第二阶段预训练8万步。ViT-L/ViT-g的批量大小分别为2320和1680,OPT/FlanT5的批量大小分别为1920和1520。使用FP16或Bfloat16量化。
- 优化器设置:AdamW,波动学习率,线性warmup等。
- 数据增强:随机裁剪和水平翻转。
Experiment
- Instructed Zero-shot Image-to-Text Generation
- 这里是把text prompt 加到 visual prompt 之后,展现了很好的泛化能力,
- 视觉知识推理:可以正确描述图像中的物体、场景、属性和关系,展示了对视觉知识的理解。
- 视觉常识推理:可以进行常识推理,描述图像之外不可见的背景信息。
- 视觉对话:可以进行多轮视觉问答,持续理解图像并生成相关回复。
- 个性化文本生成:可以结合个性化的语言风格或背景知识生成个性化的文本描述,而不仅是普遍的对象描述
- 更强的图像编码器或者更大LLM都可以提升性能。这验证了BLIP-2是一个通用的高效预训练方法,可以利用视觉和语言模型的进步。
- 这里是把text prompt 加到 visual prompt 之后,展现了很好的泛化能力,

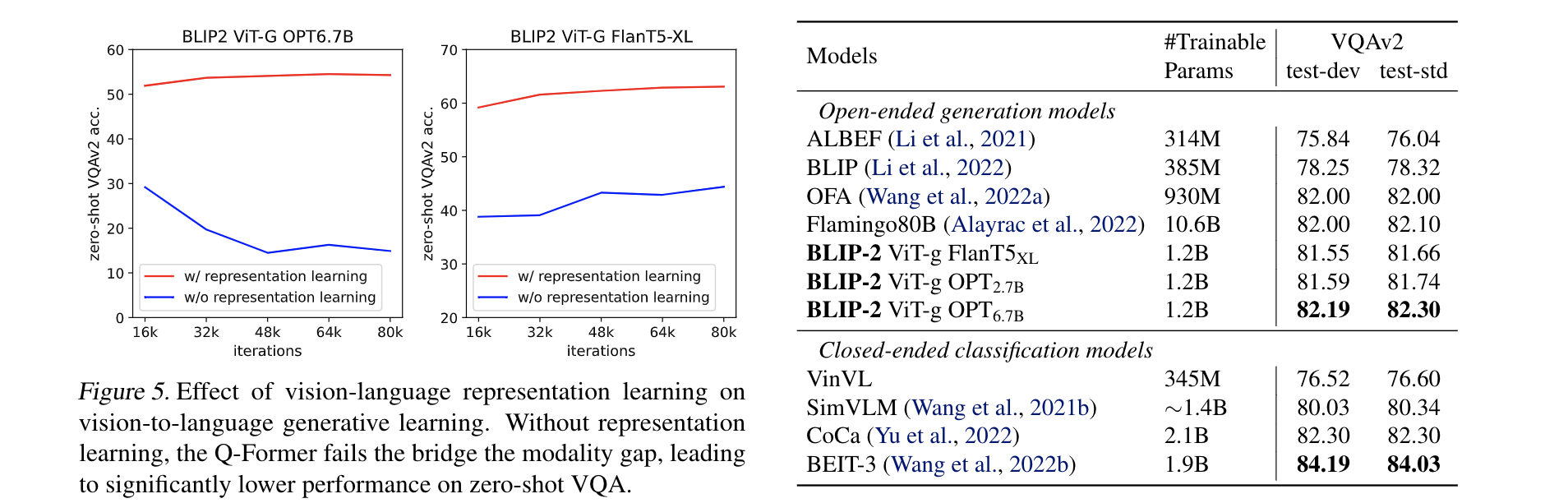
- Effect of Vision-Language Representation Learning.
- 作者说第一阶段Q-former 通过参考文字来学习视觉特征,可以降低在LLM中对齐vision-language的难度。如果没有这个阶段,就只能依赖视觉-文本的生成阶段来降低两种模态之间的gap, 图五表明了两种LLM下,缺乏这个阶段,在VQA任务上都是掉点的。
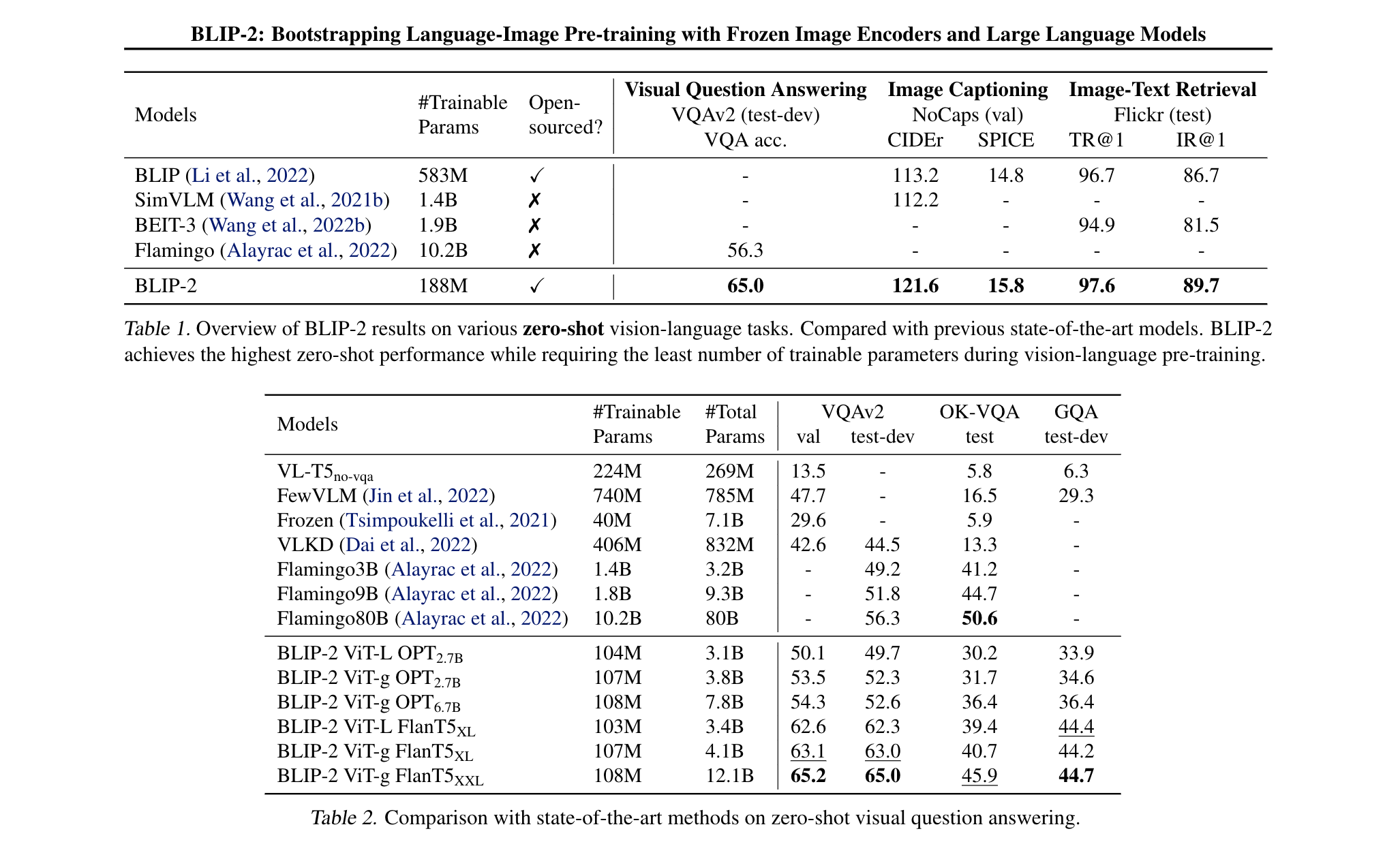
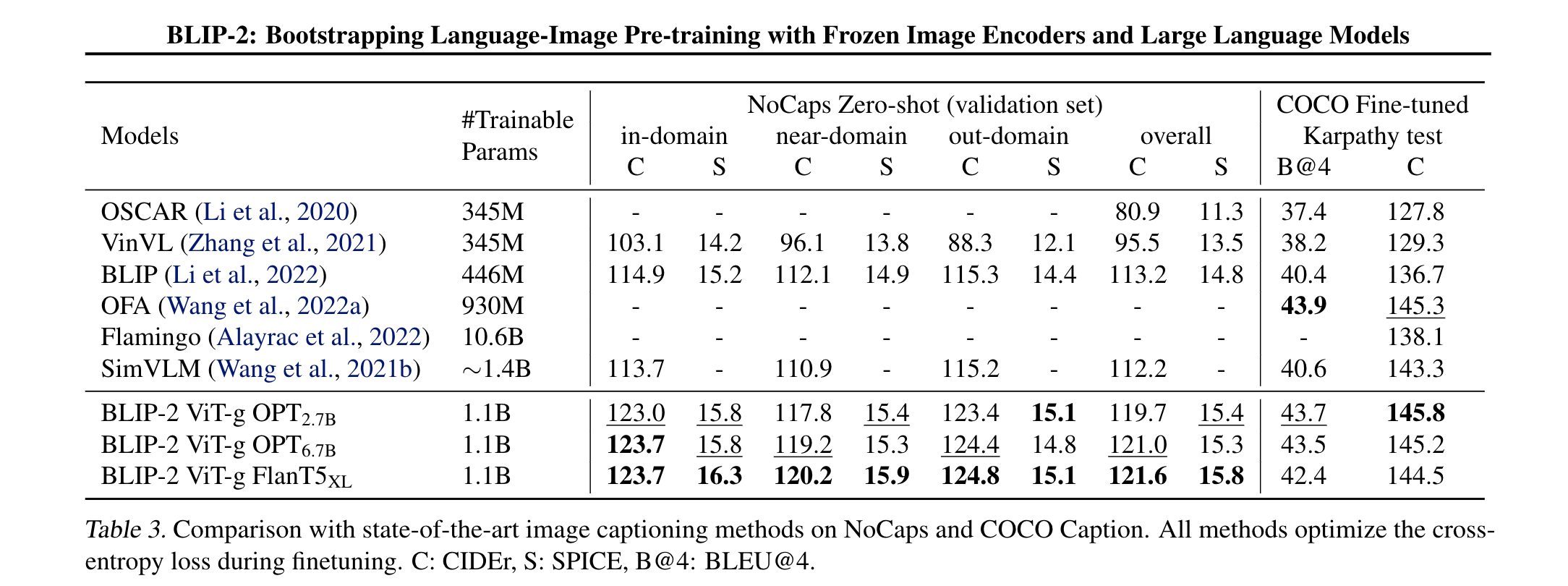
- Image Captioning
- 在图像字幕任务上,使用“a photo of”作为LLM的初始输入,生成完整字幕。只更新Q-Former和图像编码器的参数,LLM保持冻结。BLIP2 在Nocaps zero-shot 任务上取得了更好的结果
- VQA
- 微调Q-Former和图像编码器的参数,语言模型LLM保持冻结。
- 使用开放式的答案生成作为损失函数,LLM以Q-Former的输出和问题作为输入,生成答案。
- 为了提取与问题更相关的图像特征,额外使用问题来条件化Q-Former。
- 具体来说,问题的词符作为输入给Q-Former,通过自注意力层与查询向量交互,指导交叉注意力层聚焦在更有信息量的图像区域。
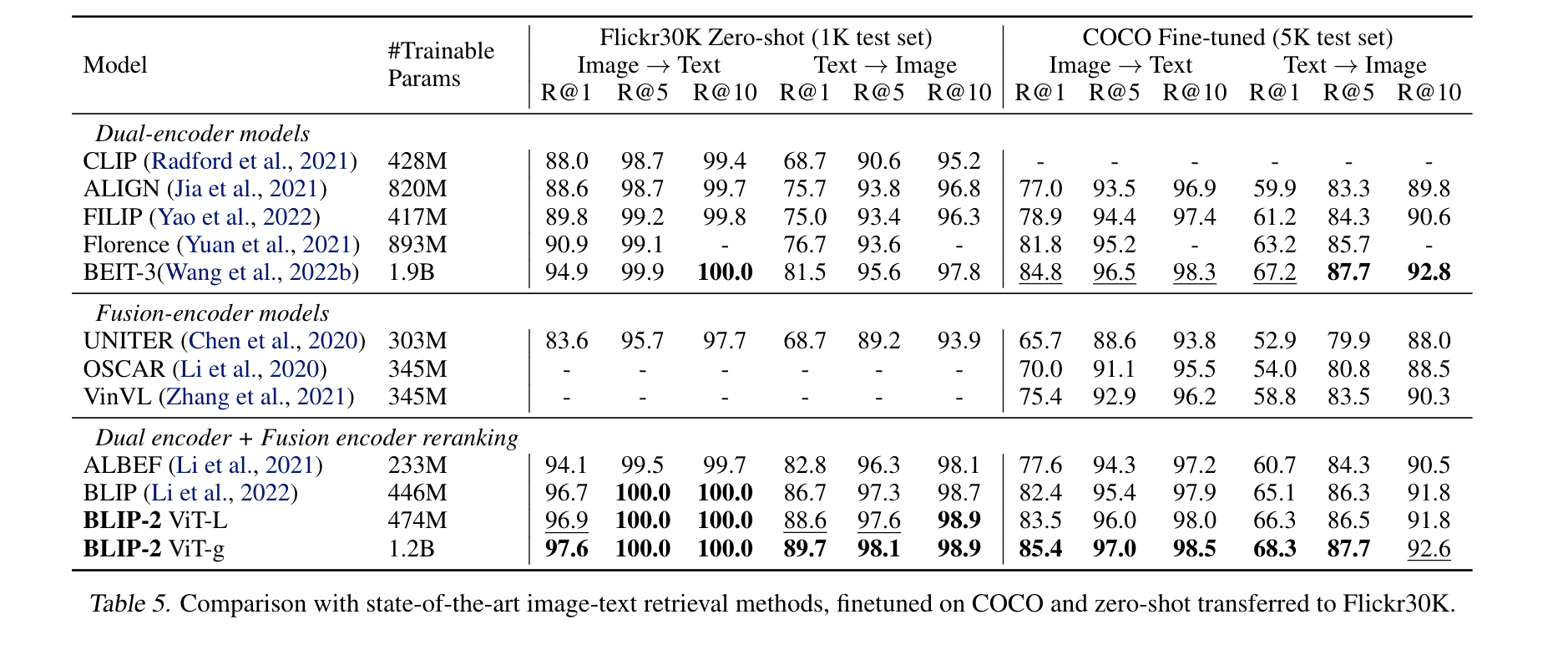
- Image Retrieval
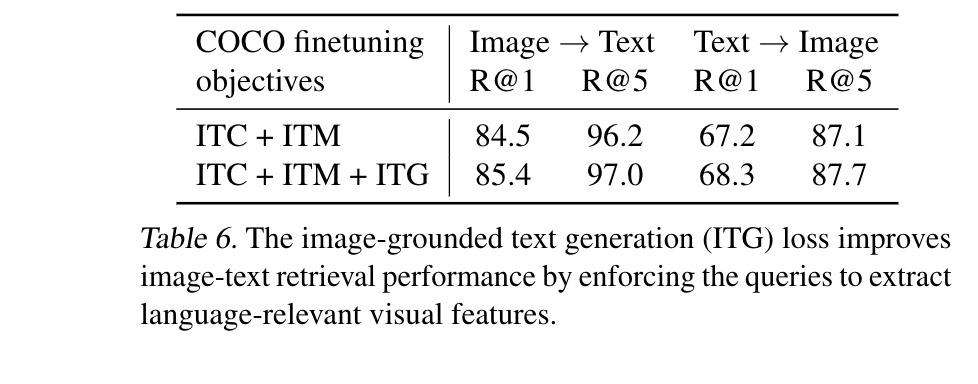
- 直接finetune 第一阶段的模型,在COCO数据集上同时微调图像编码器和Q-Former,使用与预训练相同的目标函数,包括ITC、ITM和ITG。ITC和ITM损失函数对学习图像文本相似度非常关键。实验也展示ITG损失对检索 TASK也有帮助,因为它迫使查询向量提取与文本最相关的视觉信息,提升了视觉语言对齐效果。
Thought
在limitation 里作者讨论了BLIP的一些局限性和未来的工作方向。一些现象是说,在VQA任务上,即便提供了上下文,性能也没有提升。可能是因为预训练数据集中每个样本只包含一对图像文本,语言模型无法从中学习多个图像文本对的上下文关系。
使用了冻结模型,BLIP-2也继承了语言模型的风险,如生成攻击性语言、传播社会偏见或泄露私人信息。缓解方法包括使用指令引导生成或在过滤数据集上训练