DreamFusion: Text-to-3D using 2D Diffusion
TL;DR
在Diffusion上训练百万级别的text image pair 帮助text-image 任务取得了巨大的突破。将该方法放在3D合成任务上,面临如下困难:(1)需要大量标注好的3D数据 (2)高效的3D结构 for denoising 3D data. 本文提出一种概率密度蒸馏的loss ,能够将2D diffusion model 作为先验来优化 参数化的image generator。类似DeepDream, 通过梯度下降优化一个随机初始化的Nerf,使得随机角度渲染出的2D图像达到比较低的损失。生成的3D模型,不仅可以从各个角度查看,也可以用任意光照进行重新照明,甚至合成到其他3D环境当中。这种方法无需3D训练数据,也无需修改图像扩散模型,证明了2D Diffusion 作为预训练模型的有效性。
Method
Diffusion Models and Score distillation sampling
- 作者先简单介绍了Diffusion 模型
- 训练生成模型时,使用加权证据下界(ELBO)进行训练,简化为对参数φ的加权去噪得分匹配目标。训练的过程可以被视为学习一个潜在变量模型,或者学习一系列对应于数据更嘈杂版本的得分函数。
- Classifier free Guidance: 使用了无分类器指导(CFG)的方法进行模型的训练,这种方法改变了得分函数,使其更倾向于在条件密度与无条件密度之比较大的区域。这种设置可以在牺牲样本多样性的前提下,提高样本的保真度。

- 实验中,使用了文字描述“a photo of a tree frog wearing a sweater.”(一只穿着毛衣的树蛙的照片)来对文本到图像的扩散模型进行了2D采样方法的比较。
- 对于得分蒸馏采样,使用了一个图像生成器,这个生成器将图像限制为对称的,具体来说就是使图像的左右两边保持对称,即x = (flip(θ), θ)。
HOW CAN WE SAMPLE IN PARAMETER SPACE , NOT PIXEL SPACE ?
- Diffusion 模型用在像素空间中建模复杂的分布。作者并不关注像素,目标是生成从随机角度都能渲染出良好的3D模型。
- 为了创建该模型,作者引入一种可微分图像参数化(DIP)技术,在DIP中,有一个可微分的生成器将一组参数转化为图像。他们将3D体积的参数视为输入参数,而将体积渲染器视为生成器。
- 原先diffusion 的损失函数并不适用,提出了新的采样方法,叫做得分蒸馏采样(Score Distillation Sampling,SDS)。这种方法使用的是扩散模型的得分函数而不是密度函数。得分函数可以被视为描述模型中数据点如何分布的一种方式。
- SDS的主要优点是其效率和鲁棒性。由于扩散模型可以直接预测更新方向,因此不需要通过扩散模型进行反向传播,模型只是预测图像空间的编辑。
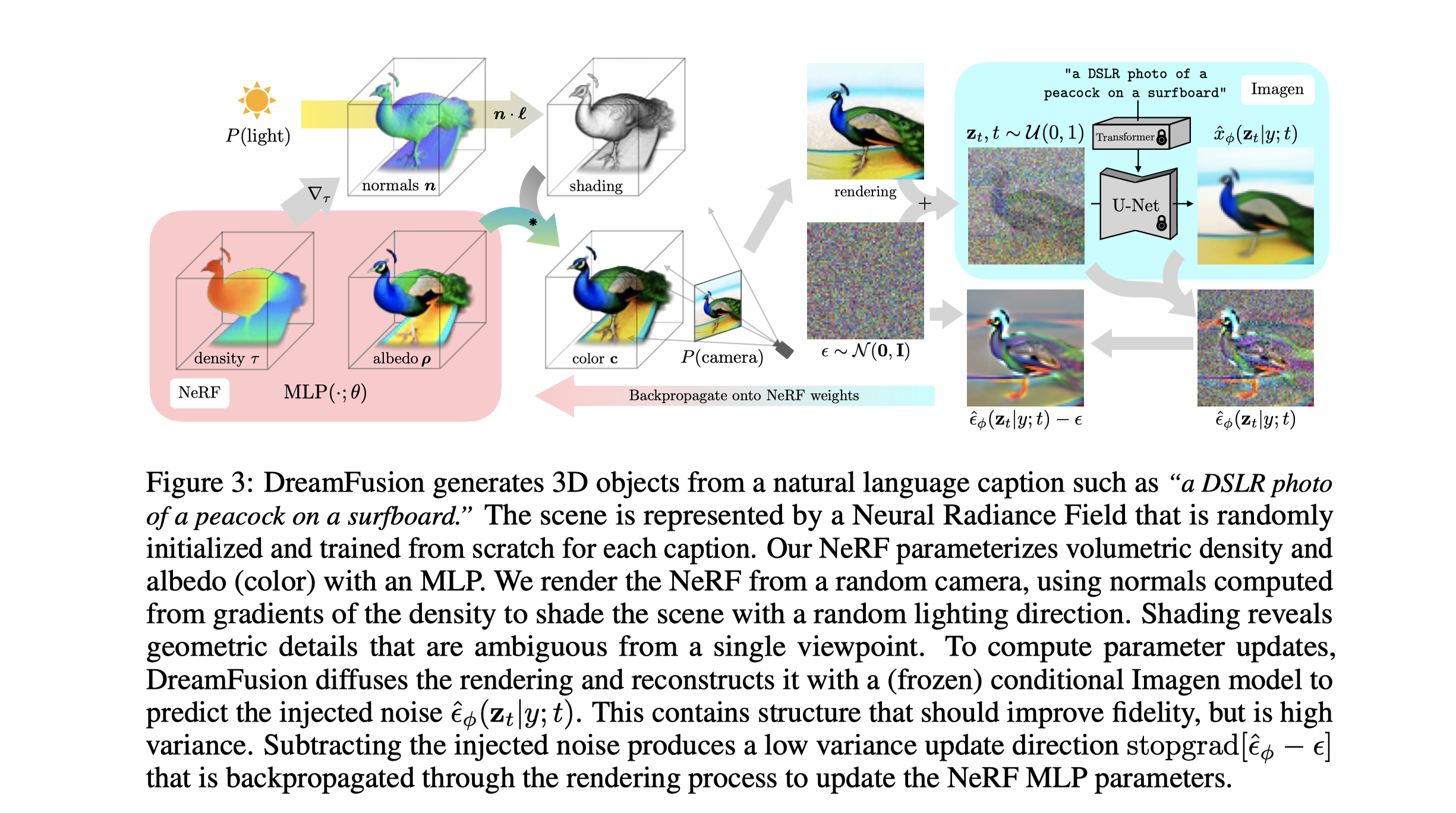
THE DREAM FUSION ALGORITHM
- 初始阶段:首先利用Imagen模型(一种预训练模型)并使用NeRF技术初始化一个随机权重的3D模型。
- 渲染阶段:接着,他们从不同的摄像机位置和角度随机渲染这个3D模型(NeRF)的视图。
- 更新阶段:这些渲染视图被用作输入,被送入一个得分提取损失函数,该函数环绕Imagen模型。然后,他们使用简单的梯度下降法更新NeRF MLP参数,使得3D模型逐步呈现出与输入文本描述相似的形状和特征。
- 阴影处理:在模型的渲染过程中,他们还对表面颜色进行了参数化,并对其进行了照明控制(即阴影处理)
- 后期优化:为了避免模型产生退化解,他们随机将表面颜色替换为白色以产生无纹理的阴影输出。同时,他们也采用了环境图和一个定向损失函数等手段,进一步优化了生成的3D模型。
text to 3d sythesis
随机采样相机和光源:在每次迭代中,首先在球形坐标系中随机选取一个相机位置,然后在该位置处生成一个相机姿态矩阵。他们还随机选取一个焦距倍数和一个位于相机位置周围的点光源位置。这一步骤中,各种不同的相机位置和距离的采样对于生成连贯的3D场景和改善学习场景的分辨率是至关重要的。
渲染:给定相机姿态和光源位置,他们将会按照之前描述的方式以64×64的分辨率渲染被照亮的NeRF模型。他们会随机选择是渲染出被照亮的颜色图,还是无纹理的图,或者是不包含任何阴影的纹理图。
视图依赖的条件扩散损失:由于文本提示通常描述的是物体的典型视图,在采样不同视图时可能并不是好的描述。因此,他们发现基于随机采样的相机位置附加视图依赖的文本到给定的输入文本上是有益的。使用了一个预训练的64×64 text2img 模型,并通过如下公式计算NeRF参数的梯度。
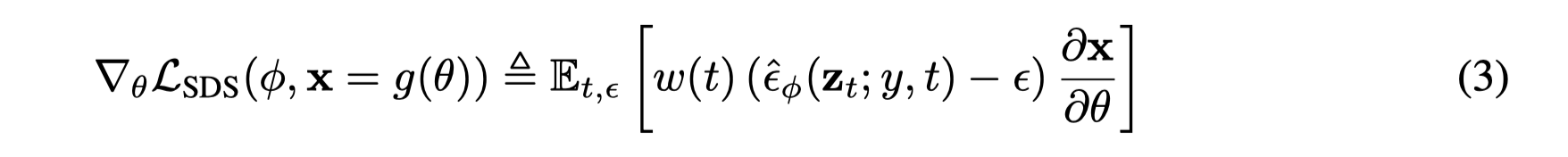
优化:3D场景在TPUv4机器上进行优化,每个芯片渲染一个独立的视图并评估扩散U-Net,每个设备的批大小为1。他们对参数进行了15000次迭代的优化,总共耗时大约1.5小时。他们使用了分布式Shampoo优化器来优化参数。

Experiment

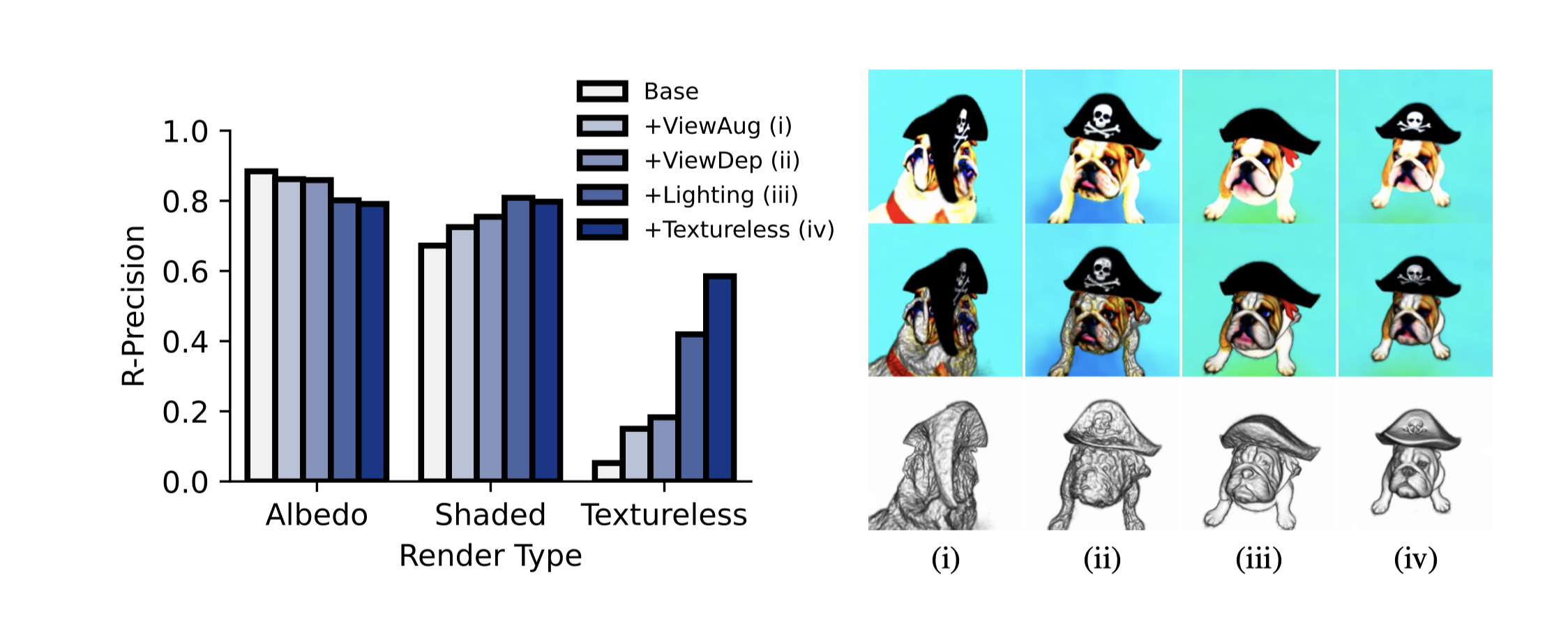
- 在对象为中心的COCO数据集上,作者使用CLIP L/14来评估我们的未照明渲染(unlit renderings)在泊松反射率(albedo)、全阴影和照明渲染以及无纹理照明几何形状方面的各个组件。
- 给出了每个消融步骤对于“一只斗牛犬戴着黑色海盗帽”这个提示在泊松反射率(顶部)、阴影(中部)和无纹理渲染(底部)的影响的可视化图。
- 基础方法(i)没有视图依赖的提示,结果是一个具有平面几何形状的多面狗。
- 添加视图依赖提示(ii)改善了几何形状,但表面非常不平滑,导致阴影渲染效果差。
- 引入照明(iii)改善了几何形状,但暗区(例如帽子)仍然不平滑。
- 无色渲染(iv)有助于平滑几何形状,但也导致一些颜色细节,如骷髅和交叉骨头被“雕刻”到几何形状中。