Autoregressive Image Generation using Residual Quantization
TL;DR
对于高分辨率图像的自回归建模,VQ方案将图像表示成离散的编码序列。短序列长度对于AR模型是非常重要,它可以减少计算开销, 因为long-range interactions of codes需要被捕捉以便于更好地预测下一个值。然而传统的VQ方案无法在减短code 序列长度的同时生成保真度搞的图像。本文方法包括两个阶段:RQ-VAE /RQ-Transformer. 固定住codebook 大小,RQ-VAE 能够精确地逼近图像的特征图,并将图像表示为离散编码的堆叠图。接着,RQ模型学会预测下一个stack 的编码来预测下一个位置的量化特征向量。由于RQ-VAE将尺寸从256压缩到8,从而也降低了RQ-Transformer的计算量。
Method
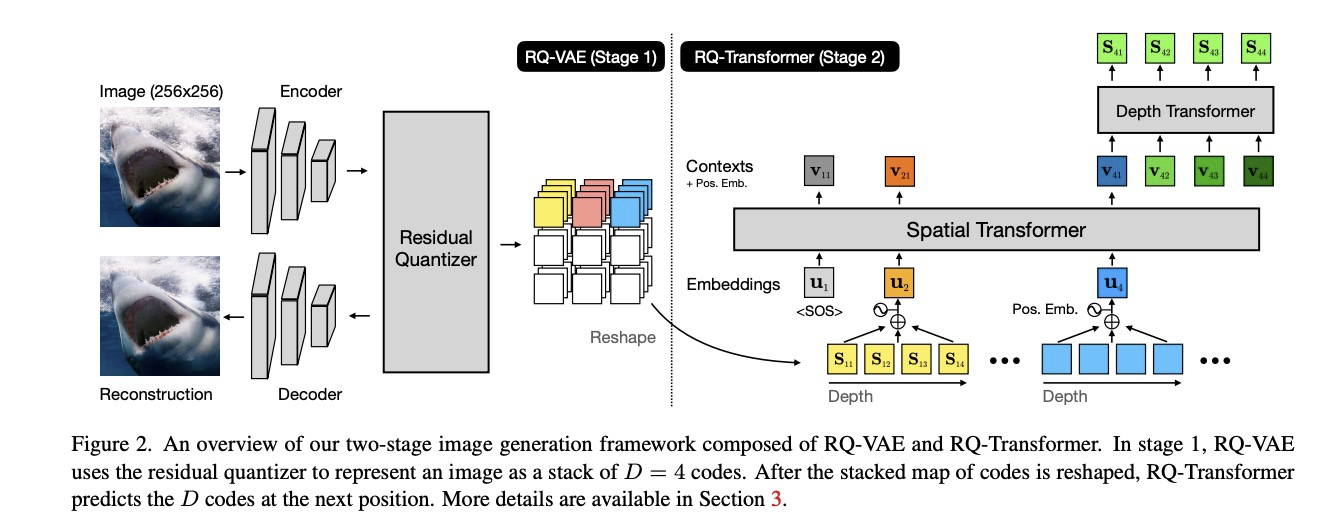
Stage1: Residue-Quantized VAE
Formulation of VQ and VQ-VAE
- VQ-VAE执行的是有损压缩,难免会涉及到尺寸H,W和保存信息之间的tradeoff. 如果VQ-VAE的codebook Size 是K,长度为HWLog2k bit. 根据 rate-distortion theory,如果要把H,W图像压缩至 H/2,W/2, 码本大小应该为 $K^4$ 才能保持重建质量。
- 其他背景知识可以参考 Codeformer, VAE , 不再赘述

Residual Quantization
- 用RQ的方式来编码向量z,将向量z 表示为有序的深度为d的编码。注意:这里RQ的编码和Codebook 的编码不是一个东西;RQ 编码的每一个码kd,对应向量z在对应深度下的残差
- RQ具体的计算流程如下,RQ采用递归 / coarse-to-fine 的方式来逼近向量z。
$$
\begin{aligned}
\text{RQ}(z; C, D) &= (k_1, \ldots, k_D) \in [K]^D \
k_d &= \text{RQ}(r_{d-1}; C, d),\ \text{for}\ d=1, \ldots, D \
r_d &= r_{d-1} - e(k_d),\ \text{for}\ d=1, \ldots, D \
z^{\hat{ }}d &= \sum{i=1}^d e(k_i),\ \text{for}\ d=1, \ldots, D \
z^{\hat{ }} &= z^{\hat{ }}_D
\end{aligned}
$$- 这里对于每一个深度,共享同一个codebook。如果codebook 对每个深度都是独立的,那么每个深度的codebook size会不同,会导致更加复杂的超参数搜索。当RQ和VQ codebook相同时,由于RQ存在残差编码,每个深度的空间都是D,因此聚类的数目可以是 $K^D$RQ
RQ-VAE

- loss 则是熟悉的重构loss + commitment loss。 sg代表stop gradient 操作
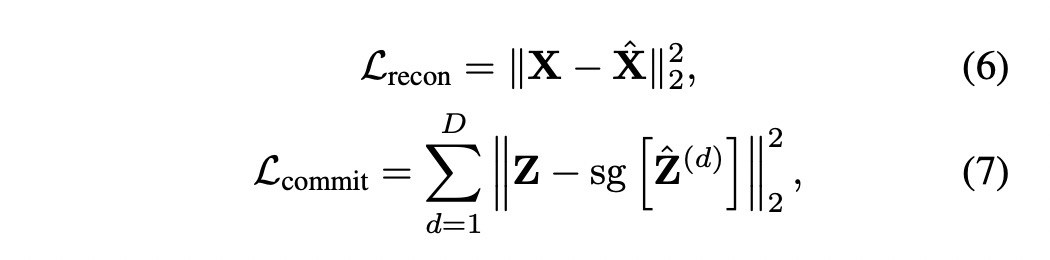
Stage2: RQ-Transformer
AR Modeling for Codes with Depth D
- RQ-VAE提取出codemap $M \in [K]^{H \times W \times D}$, 然后 reshape 成一个二维数组 $S \in [K]^{T \times D}$, 取它的第t行表示为 $St = (St_1, \dots, St_D) \in [K]^D,t \in [T]$,每行长度为d。
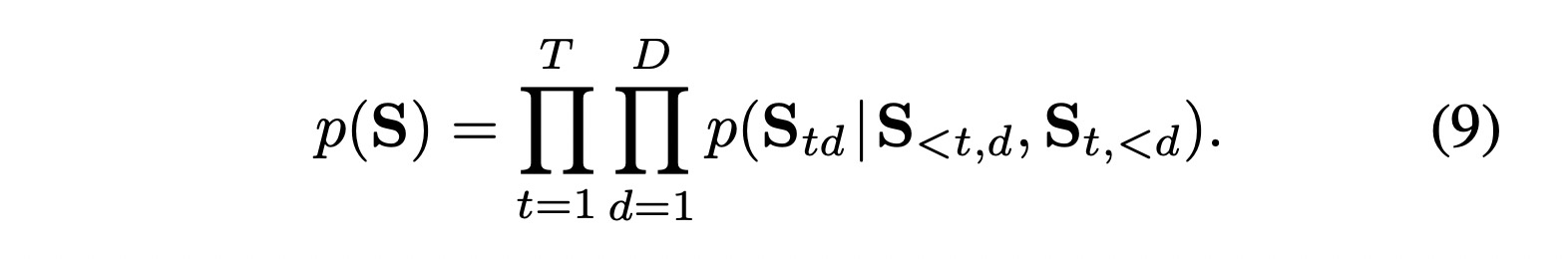
- RQ Transformer 包括Spatial Transformer 和 Depth Transformer,Spatial Transformer 的输入可以表示为
$u_t = \text{PET}(t) + \sum_{d=1}^D e(St_{t-1,d}) + X$
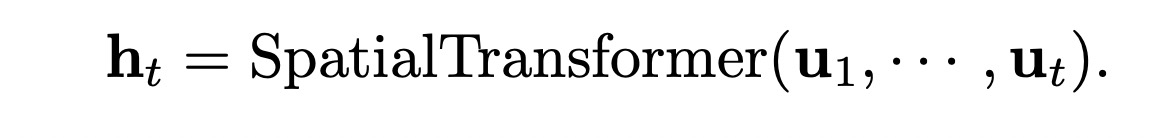
Depth Transformer
$v_{td} = \text{PED}(d) + X + \sum_{d_0=1}^{d-1} e(St_{t,d_0})$
$L_{AR} = \text{ESE}{t,d}[-\log p(St{t,d} | S_{<t,d}, St_{<d})]$
we为了解决exposure bias问题,提出了 soft labeling 和 stochastic sampling
of codes from RQ-VAE 两种方法。exposure bias 指的是训练和推理时序列生成过程中产生的偏差。训练时先前的符号都是来自GT,而推理时错误可能会被不断累积。softlabel指的是 NLL损失在这里使用 $Q_t(\cdot | rt,d-1)$作为 $S_{td}$ 的监督信号; stochastic sampling指的是从$Q_t(\cdot | rt,d-1)$采样一个编码作为残差的编码,可以增加泛化性。
Experiment
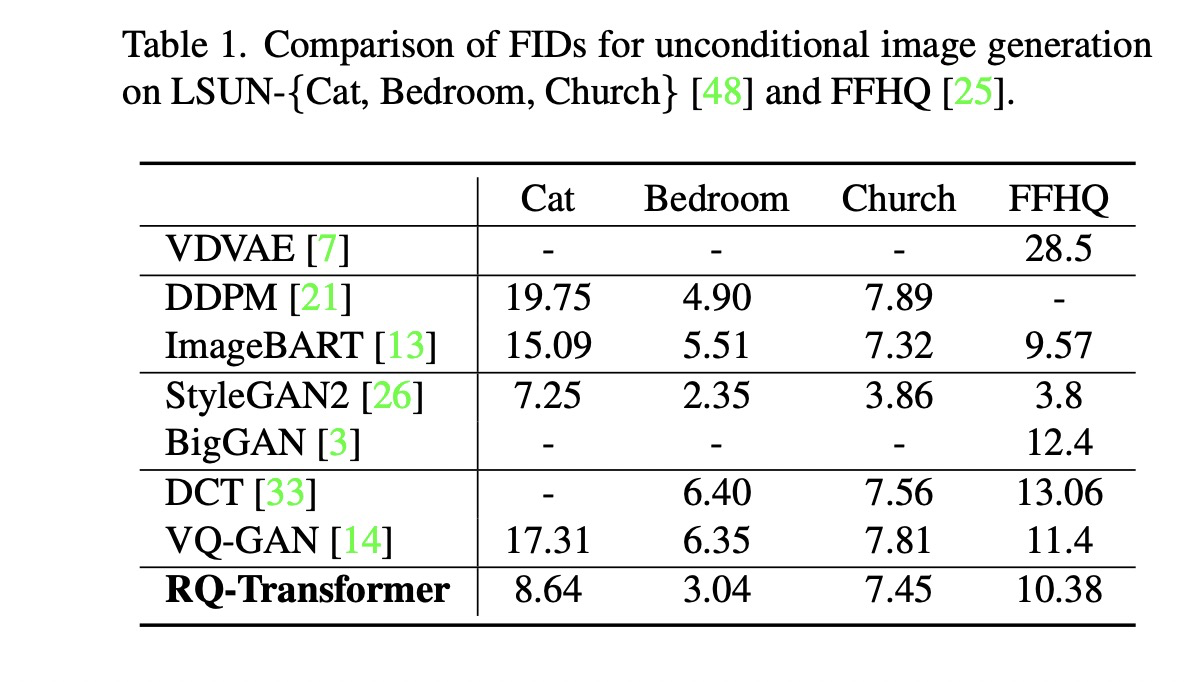
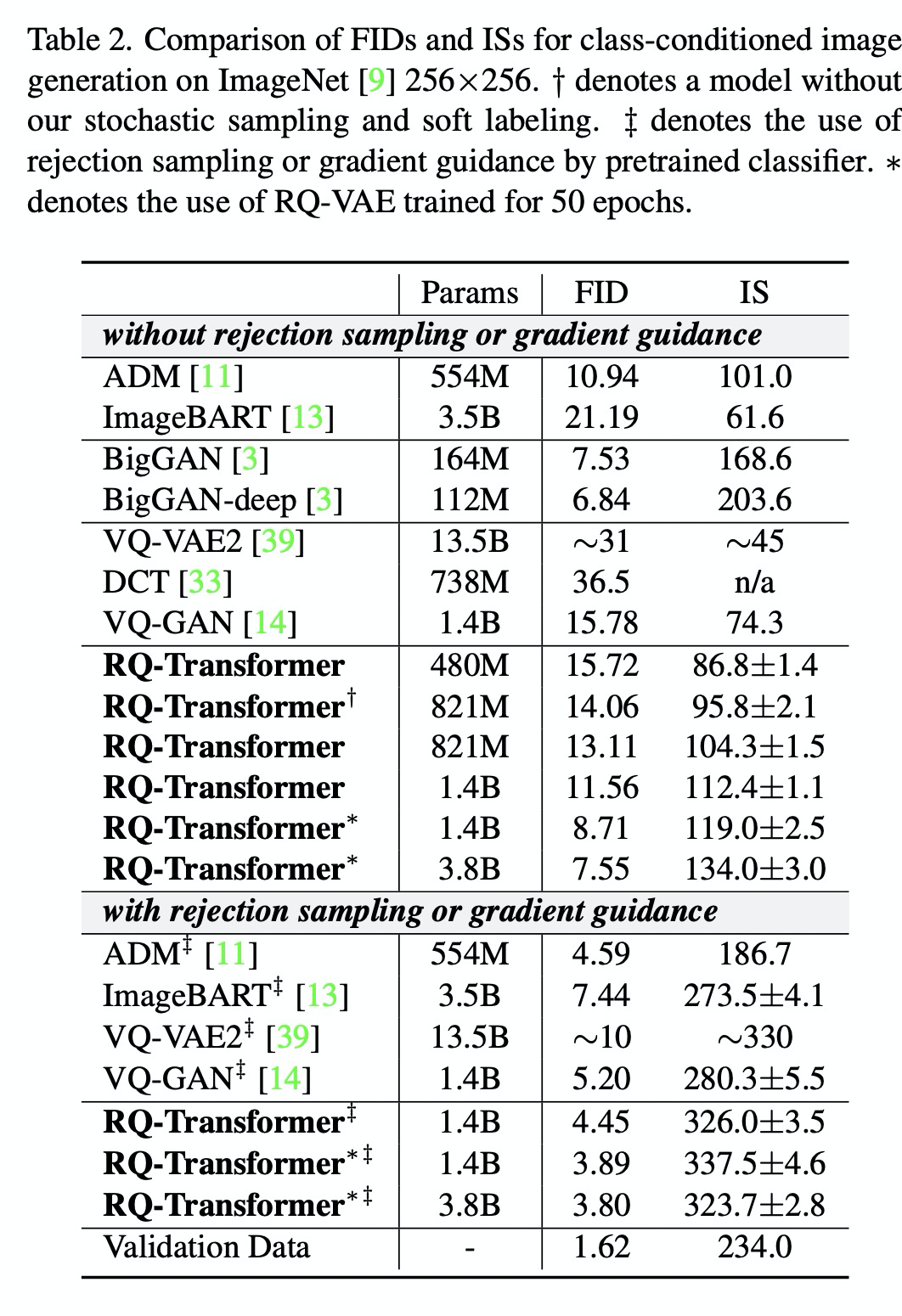
- 做了Unconditioned 和 Conditioned 图像生成的比较
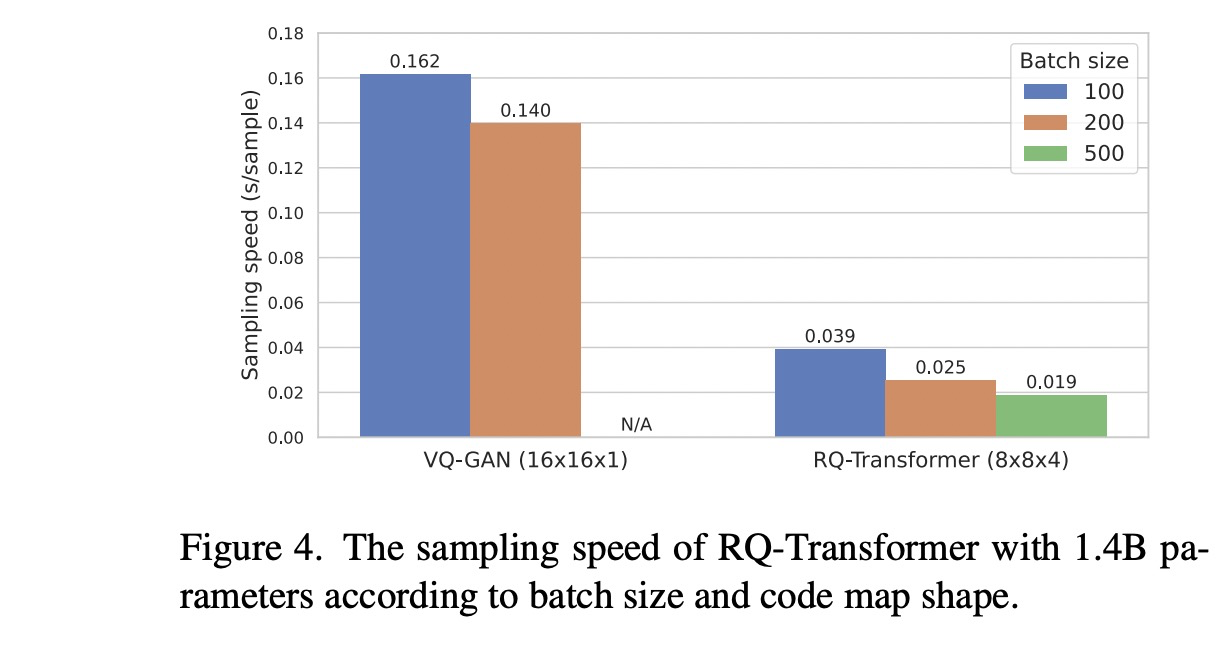
- 对比VQ-GAN 和 RQ-Transformer 的采样速度,在batch size = 100 / 200 条件下有着四到五倍多的加速比。
- Ablation
- 提升depth比提升codebook的size更加有效
- 通过depth share codebook机制提升了codebook的利用率
Thought
Depth 的引入,用recursive的形式来表示表示codebook,降低冗余程度,压缩密度更高