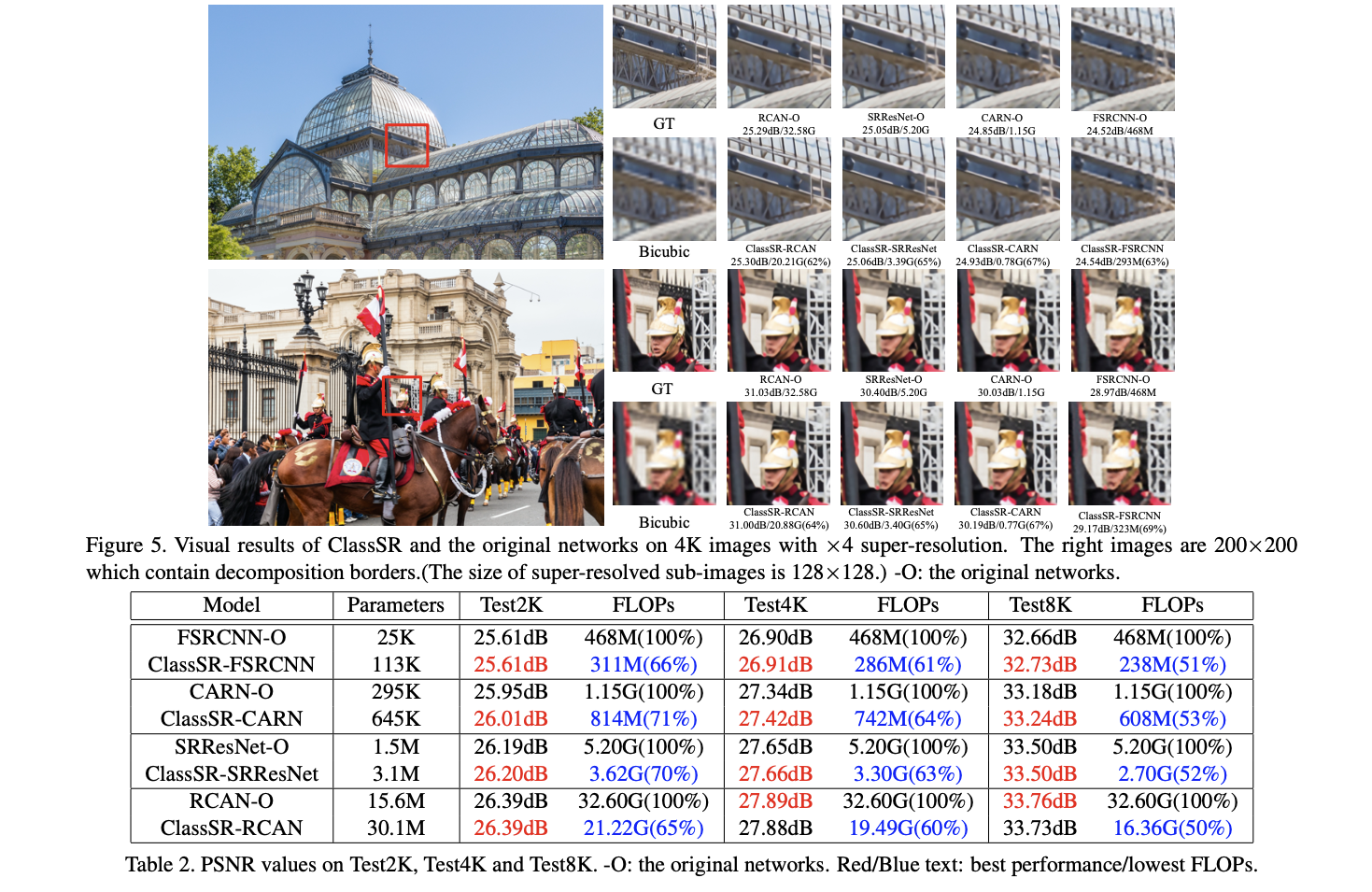
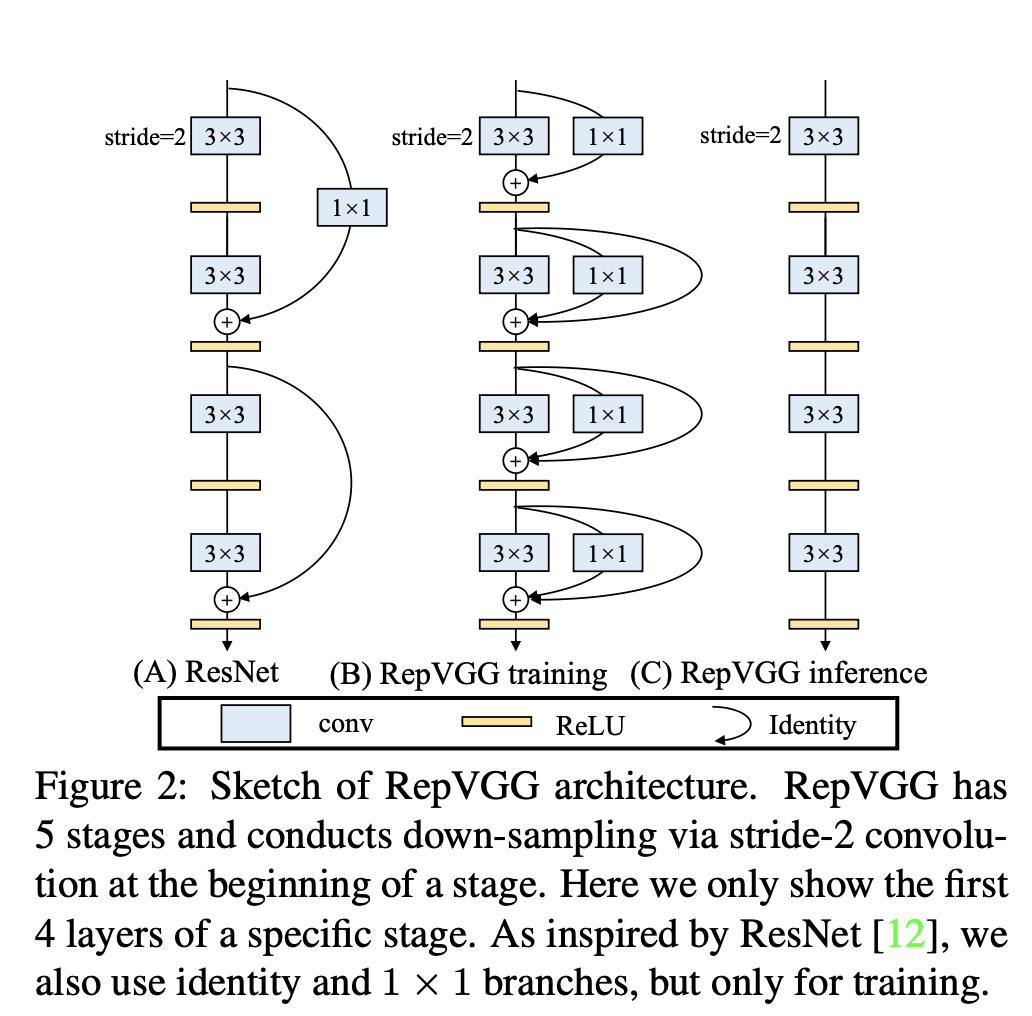
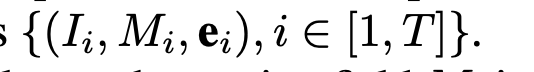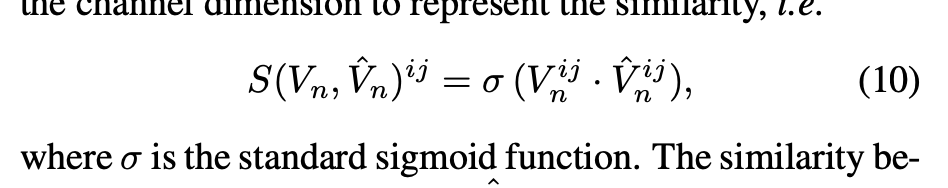Realistic Image Super-Resolution
TL;DR
GAN-based 的方法在生成details的同时也会引入artifacts。作者发现在artifacts area的 residue variance 和 visual-friendly 的区域有显著的不同,设计上利用生成的artifacts map 来对训练过程进行正则。

Method
GAN-SR induced visual artifacts
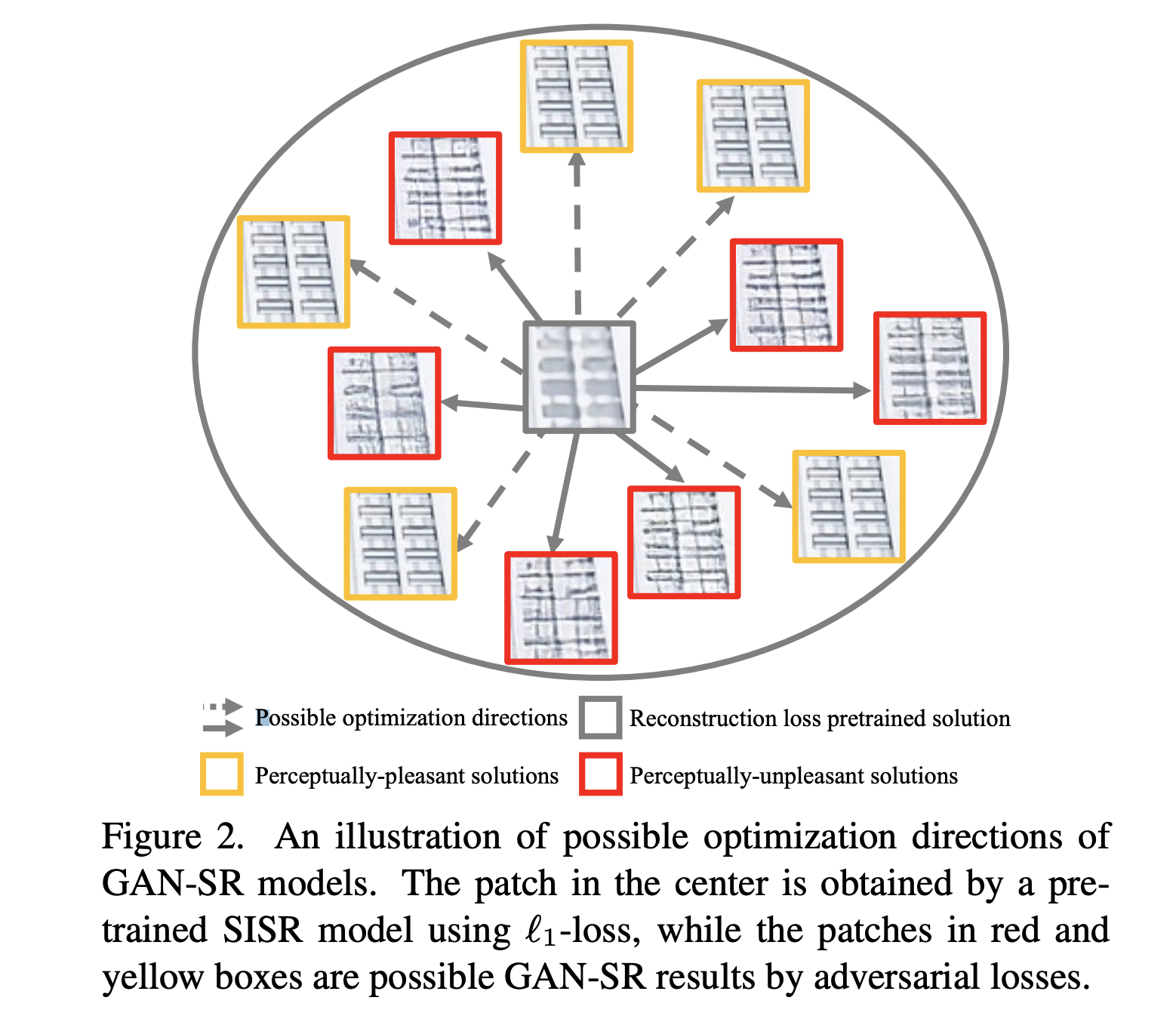
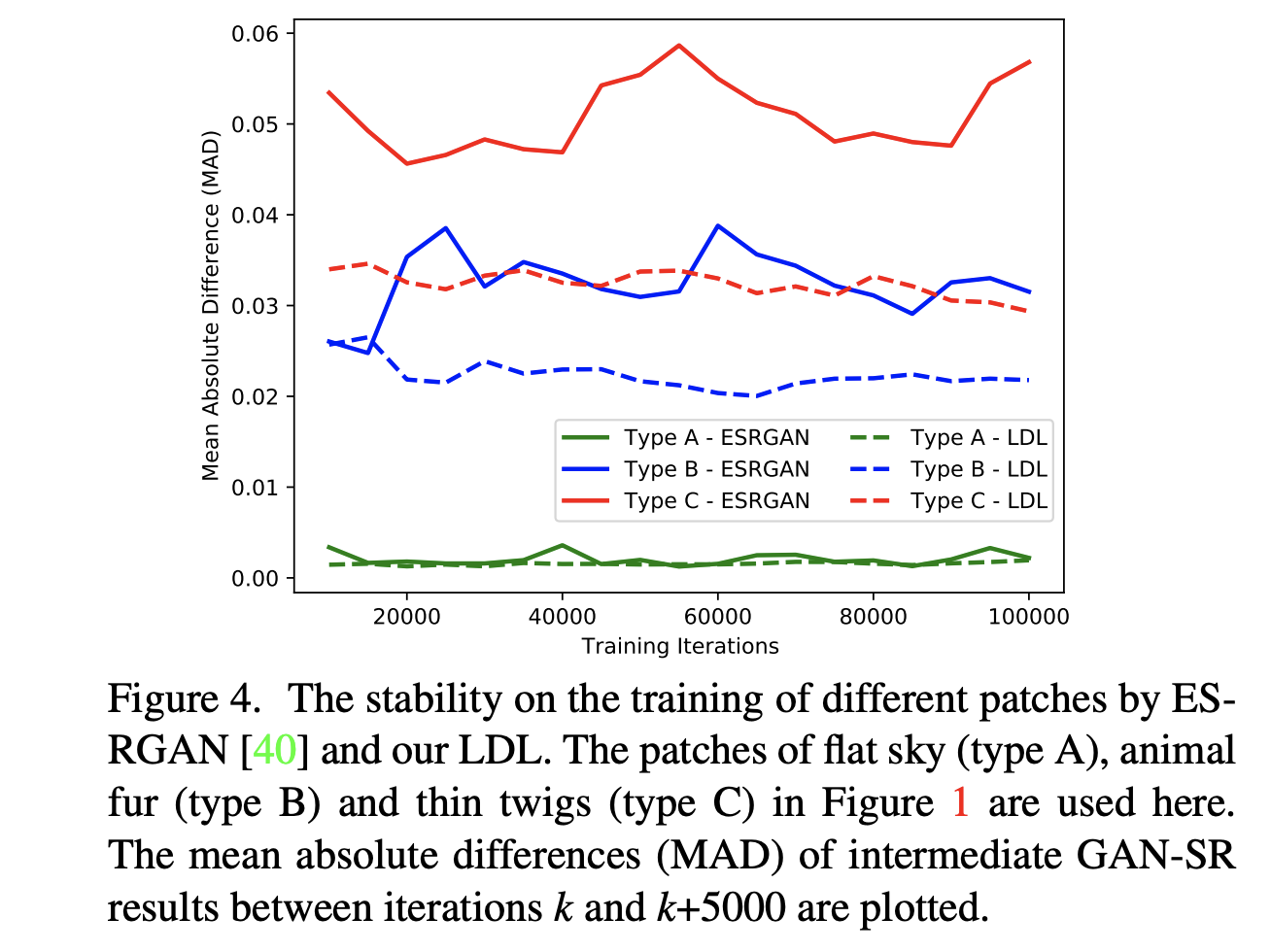
- Reconstruct loss 使得结果趋于blurred average, Adv loss 会产生更多细节。由于从一个blur image 开始,SR存在多组解。GAN loss 会把结果引入多个方向。

- 对于type B 的texture,由于在小区域内的分布是相对随机的,因此很难看出差别
- 对于type C 的texture,包含 regular & sharp transitions, 在降质后这些pattern 在LR patch 中就消失了。采用原先的GAN方法,它在训练当中的variation 是相当高的
Discriminating artifacts from realistic details

- 生成一张artifacts map, 它的通道数为1. 首先将SR的结果和GT做差,提取出high frequency的部分
- type B / C 的 Residue 图赏可以看出,他们的差异很大。type B 的Residue 分布依然比较随机,本文采用如下方式计算Residue的方差。经验上把这个窗口的大小设为7.
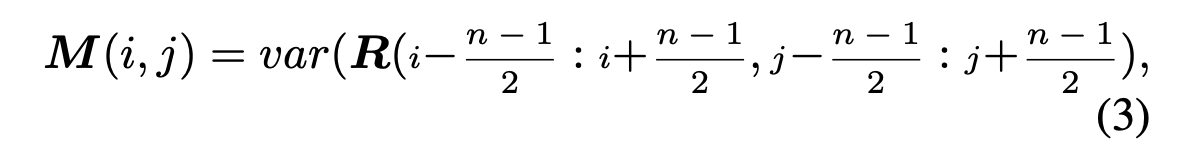
- 为了使得训练过程更加稳定,用指数对方差进行scale 上的调整
- 用moving average方法来使的训练过程更稳定。该方法有两个输出,其中用EMA方法输出的结果更稳定,用原SR结果生成的细节则更多。当R1 > R2时,则用Refinment map 对结果进行惩罚。
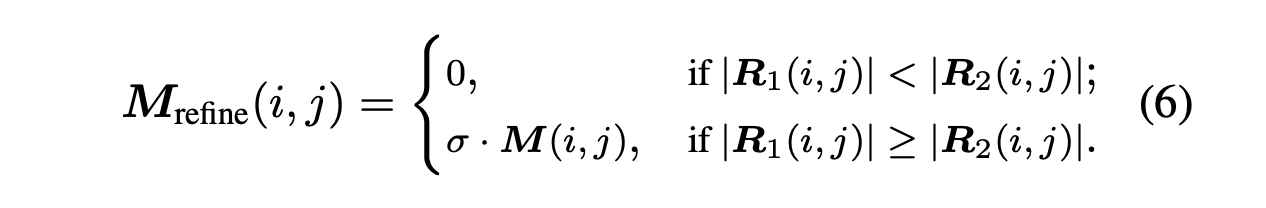
Loss

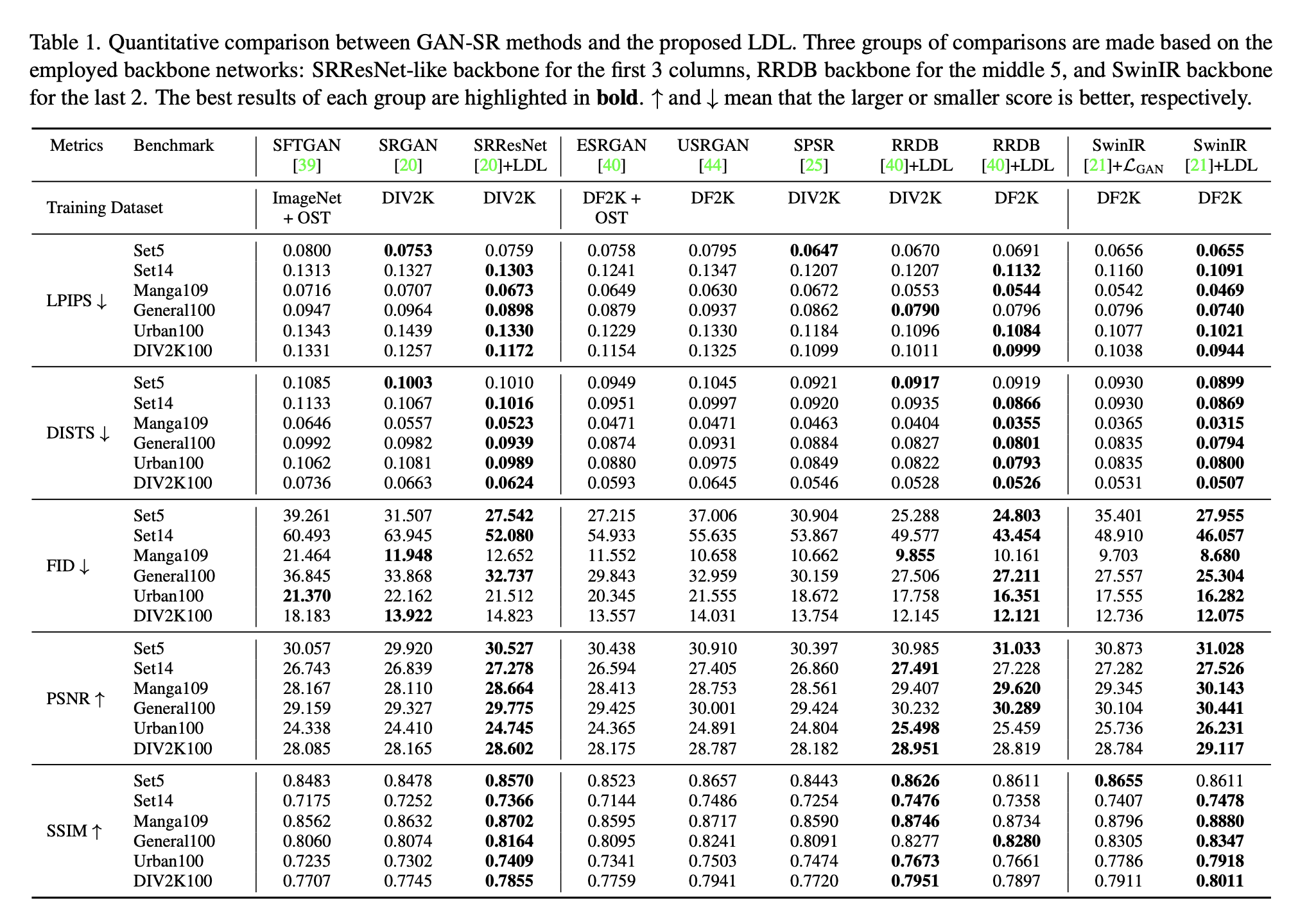
Experiment