SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
TL;DR
SDXL 使用了三倍大小的UNet Backbone,主要体现在:更多的attention block, 更大的cross attention context 作为第二个text encoder。 设计了多种条件机制,并且在SDXL上使用多种aspect ratio 进行训练,最后引入一个refine model 来给SDXL做后处理。
Code: https://github.com/Stability-AI/generative-models
Model weights: https://huggingface.co/stabilityai/
Method
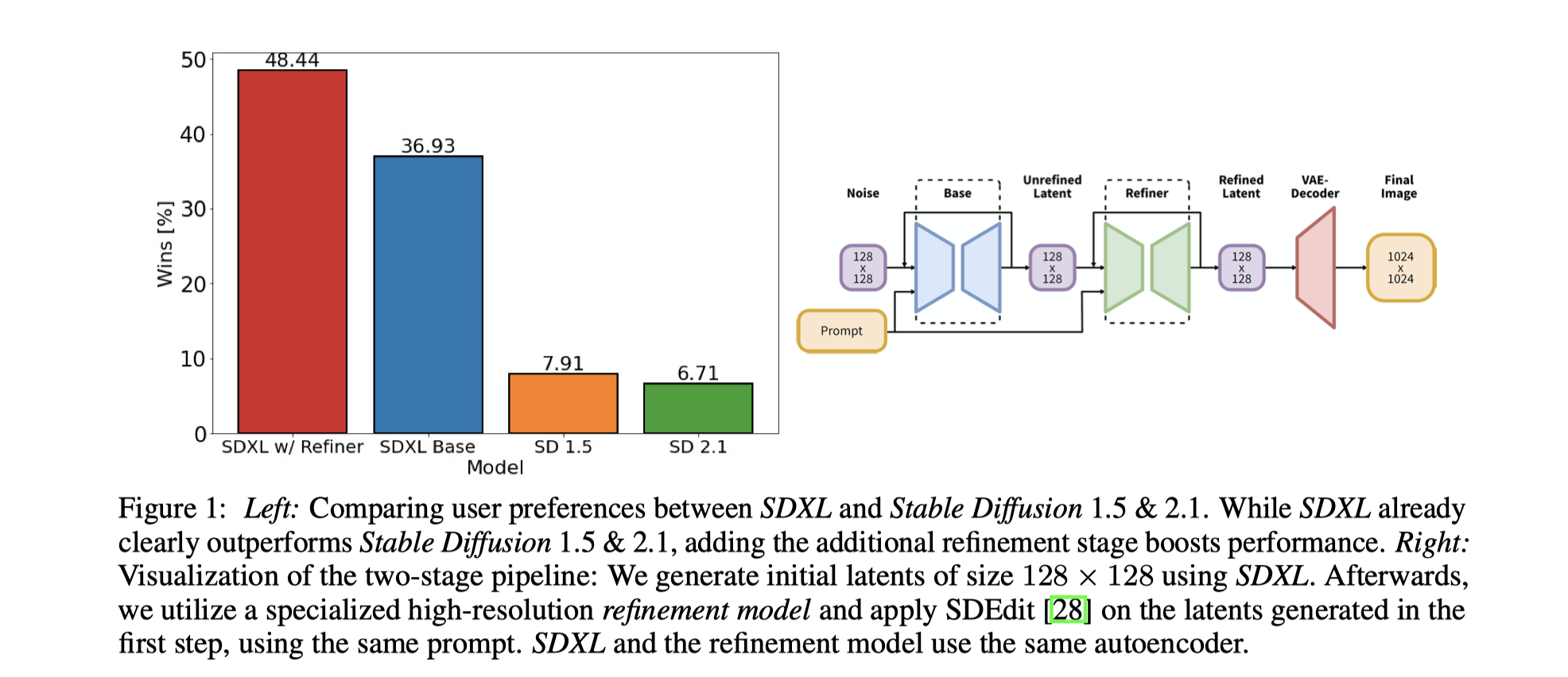
- 两阶段pipeline: 首先使用SDXL生成初始128 x 128 大小的latent ,其次利用一个专门的高分辨率refinement 模型,和SDEdit 方法作用在第一次输出的latent 上(使用相同的prompt)。SDXL / Refinement model 使用相同的自编码器。
Architecture & Scale

- Contrast
- 在UNet 参数上,几乎是以前的三倍
- 在UNet 当中的Transformer 模块的分布做了一些调整,去掉了8X downsample, 也增加了低分辨率上transformer 的数量。这里主要的原因是因为效率
- Text Encoder 方面用了OpenCLIP Vit BigG 和 CLIP Vit-L
- context dim 的大小也增大了不少
Micro-Conditioning
Conditioning the Model on Image Size
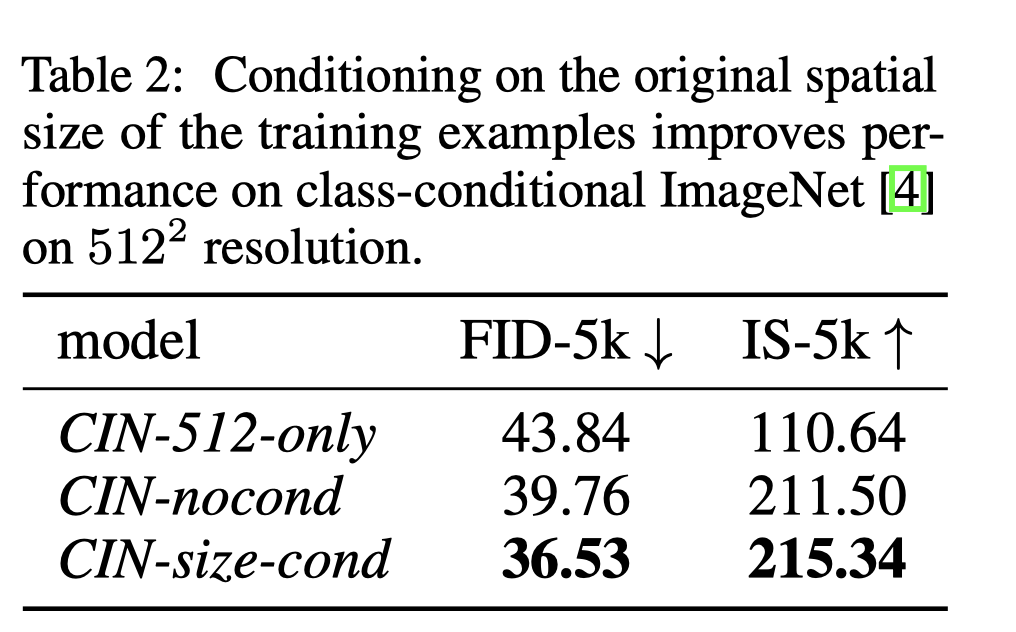
- 将原始的输入输出size 当作condition 注入。利用傅立叶特征编码对每个部分单独计算嵌入。这些编码最终concat 成一个向量,然后和time embedding 相加。

- 512 only 因为存在overfit 现象,效果很差;CIN-size-cond 的FID和IS都很高
Conditioning the Model on Cropping Parameters
- 可以看出SDXL相比之前的版本,Crop问题有更好的表现
- 再设置一个condition, 一共包含top, left 两个元素。在训练神经网络时,防止随机裁剪造成的数据泄露问题:在数据加载阶段,提出了均匀采样裁剪坐标的方法,将它们通过傅立叶特征嵌入作为条件参数输入模型,从而增强了图像合成过程的控制。


Multi-Aspect training
- 分桶训练:将数据分为不同宽高比的桶,每个训练批次由同一桶中的图像组成,并在每个训练步骤中交替使用不同大小的桶。
- 尺寸条件化:模型接收桶大小(或目标大小)作为条件输入,以整数元组 $c_{ar}$ = ($h_{tgt}, w_{tgt}$ )的形式表示,并以类似于之前描述的尺寸和裁剪条件的方式嵌入到傅立叶空间中。
- 多方位fintuen:在固定宽高比和分辨率的预训练模型之后,进行多方位训练作为微调阶段,并将其与第2.2节中介绍的条件技术结合,通过沿通道轴连接。
- 裁剪条件化与多方位训练互补:裁剪条件化和多方位训练是互补的操作,裁剪条件化只在桶边界(通常为64像素)内工作。然而,为了简化实施,选择保留这个控制参数用于多方位模型。
Improved Autoencoder
- 用了更大的batchsize
Putting everything together
- 在latent 空间使用单独的LDM来处理高频数据