ViLT: Vision-and-Language Transformer
Without Convolution or Region Supervision
TL; DR
VLP 大幅提升了 joint vision-language 下游任务的效果。现有方法主要依靠image feature extraction 的过程,主要包括ROI 区域的监督和卷积结构。痛点:(1)efficiency / speed :直接提取图像特征需要额外的计算量(相比多模态交互)(2)表达能力的上界受限于 visual embedder 和 predefined visual vocabulary(预定义好的视觉词汇)
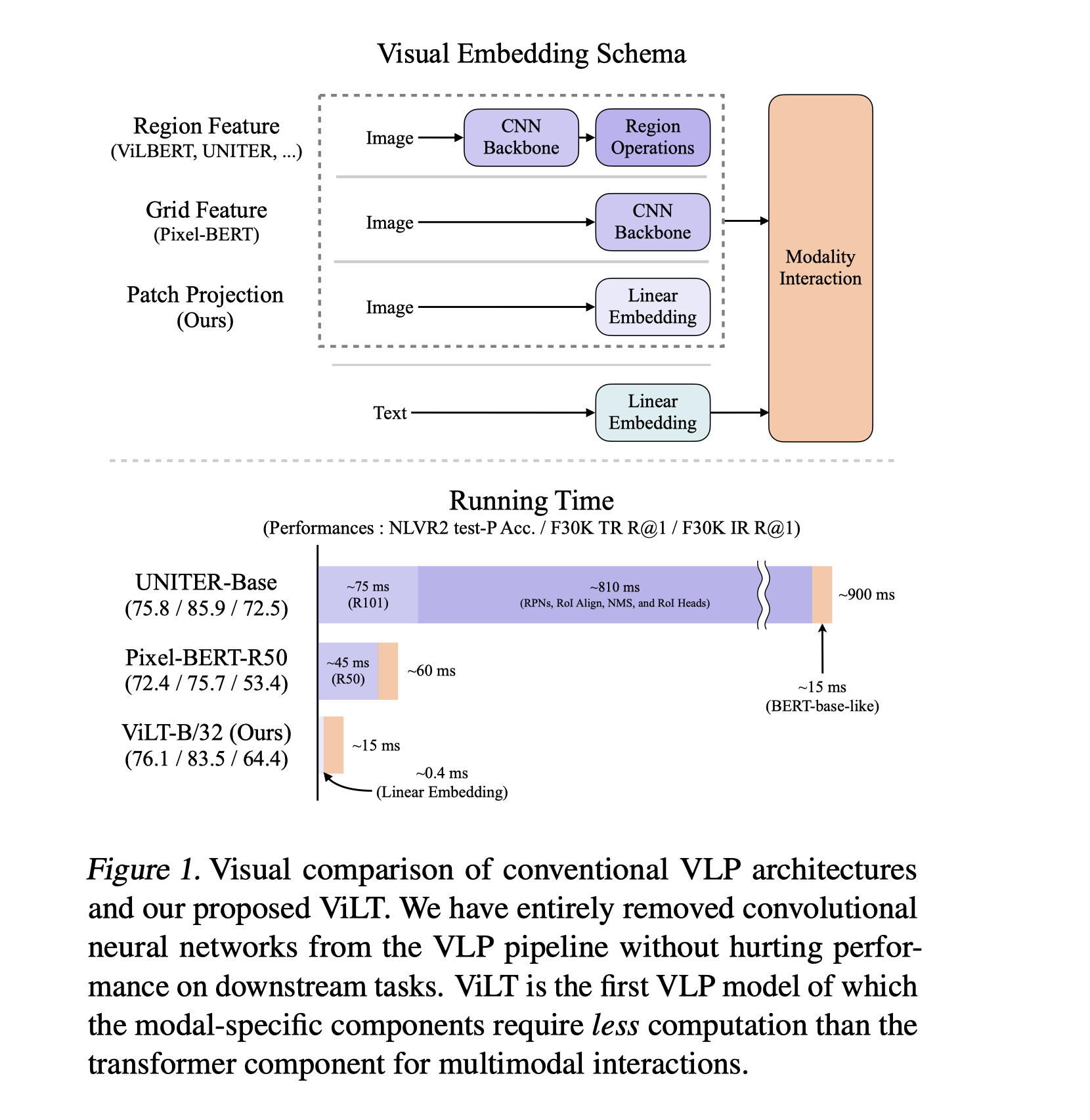
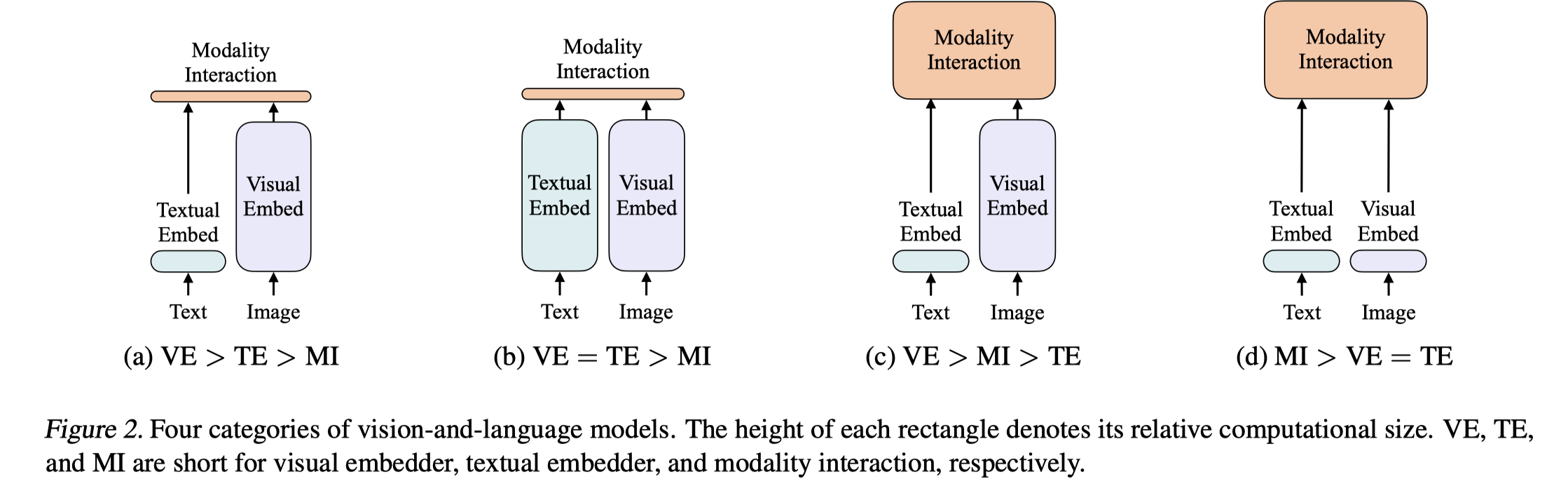
- 常见的四种vision language model. VE / TE / MI 分别代表视觉嵌入器 / 文本嵌入器 / 多模交互。其中越高则表示计算量越大
Method
Overview
- ViLT(视觉语言变化器)采用了简单的视觉嵌入流程和单流方式。它和其他方法的区别是:它从预训练的ViT 而不是BERT 来初始化交互变换器的权重。这种初始化主要是为了应用交互层的视觉特征能力,而无需单独的视觉嵌入器。
- Vit 包括 MSA,MLP层,它和BERT比较大区别在于:BERT是 post-norm, 即 layer norm 在MSA,MLP之后,Vit 中的layer norm 则在之前。
- 输入文本经过 word embed Matrix 和 位置编码矩阵得到词嵌入。输入图像则经过切块,展开之后,经过线性映射和位置编码,最终得到嵌入向量。text 和 image 先沿着各自模态求和,然后concat 得到一个向量z0,这个向量再经过depth transformer 反复进行迭代。p 表示对模态输入的第0维,做一次线性映射然后再取正切。
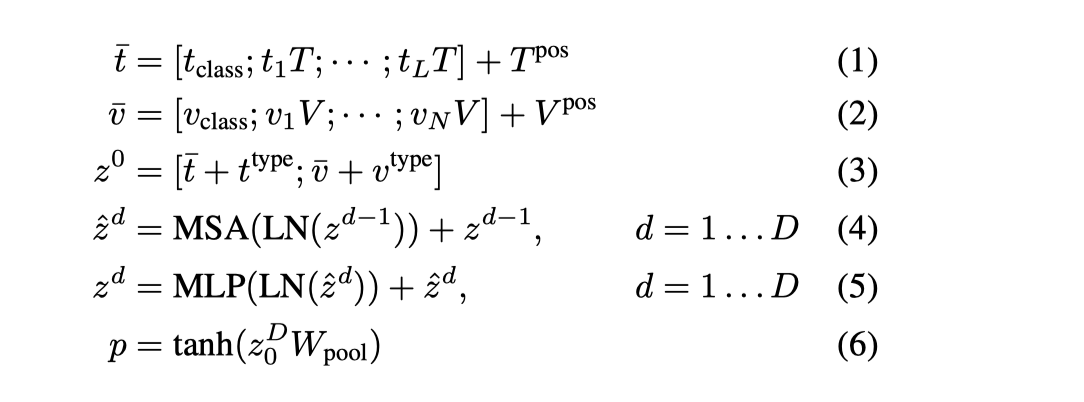
- 模型使用的weight 来自于 ViT-B/32
Pre-training Objectives
- 模型训练ViLT 使用了两个常用的目标
- ITM(Image text matching)图像文本对齐:在处理过程中,随机把原有的对齐图像以0.5的概率替换成另一张不同图像。ITM头部使用一个线性层将pool的输出特征p投影到二元类上,然后计算-log似然作为ITM损失
- 词片对齐(word region alignment)。WPA使用不精确的近端点方法(Inexact Proximal Point method,IPOT)计算zD的两个子集(文本子集zD|t和视觉子集zD|v)之间的对齐得分
- MLM (Masked Language Modeling): 目标是从 $z_{masked}^{D} | t$ 去预测 $t_{mask}$(mask text token). 使用两层MLP,MLM head, 输入 $z_{masked}^{D} | t$ , 输出词汇表上的logits值,然后计算损失。
Whole word masking
- whole word masking 是指把所有连续的sub word 全部屏蔽,这个技术重要的原因是,希望可以充分利用另外模态的信息,避免直接从被部分屏蔽的sub words 中预测出整个词。
Image Augmentation
- finetune 过程中使用了RandAugment, 避免使用颜色反转和crop
Experiment
Overview
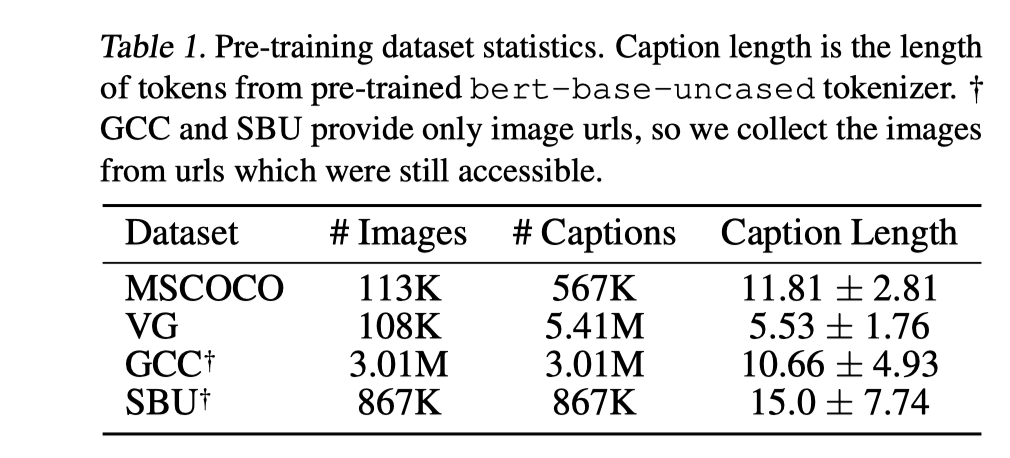
- 在以下数据集中进行预训练
Implementation Details
- lr: 1e-4, weight decay: 1e-2. 前10%时进行warm up
- 保持图像的长宽比不变,短边限制在384,长边限制在640。对于640X384的图像,ViLT-B/32 会产生12 x 20 个patch 。大部分情况patch 数量在200 左右。
- 训练使用了64块V100,batchsize=4096;
Classification
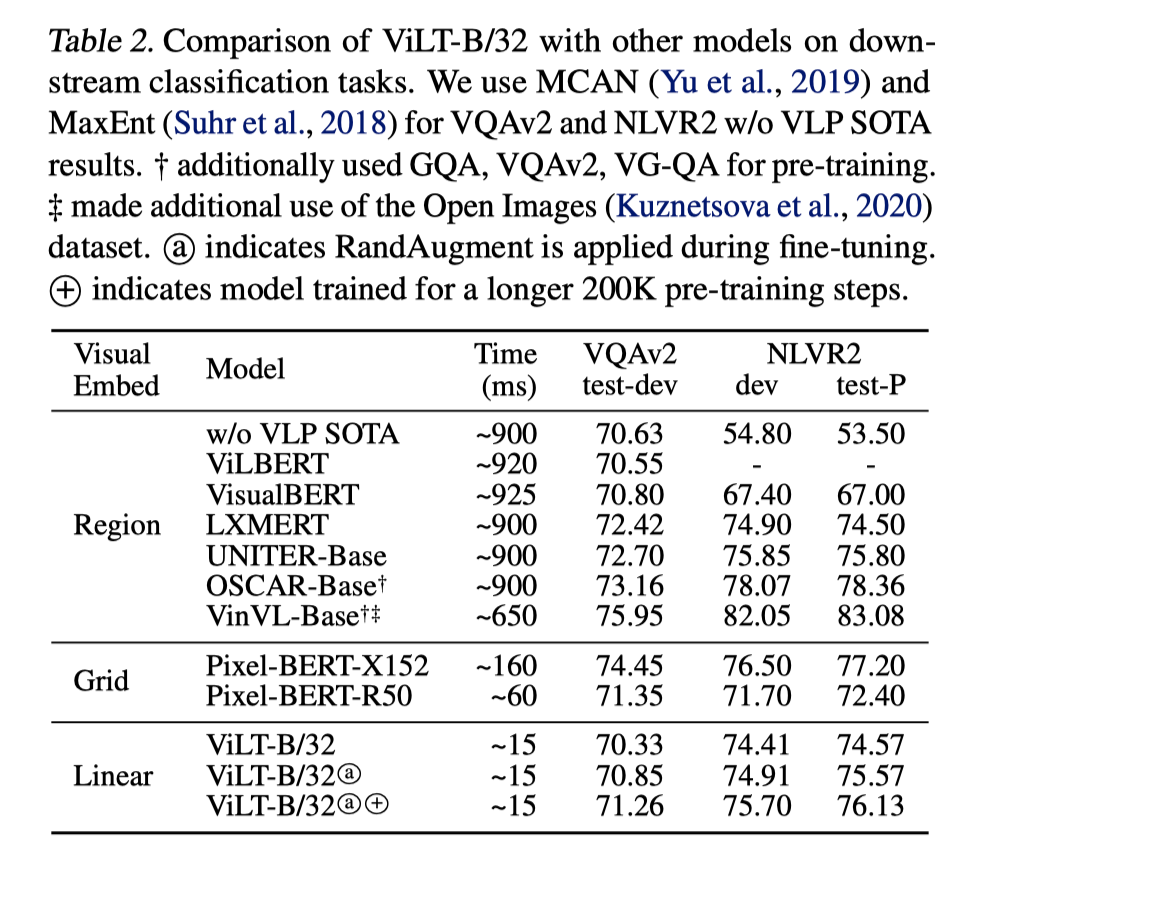
- 与其他配备了大型视觉嵌入模块的视觉语言预训练模型相比,ViLT 在 VQA 得分上表现得略有不足。这可能是由于对象检测器生成的独立对象表示能够简化 VQA 的训练,因为在 VQA 中,问题通常是针对特定对象的。
- Visual Reasoning 上结果还不错
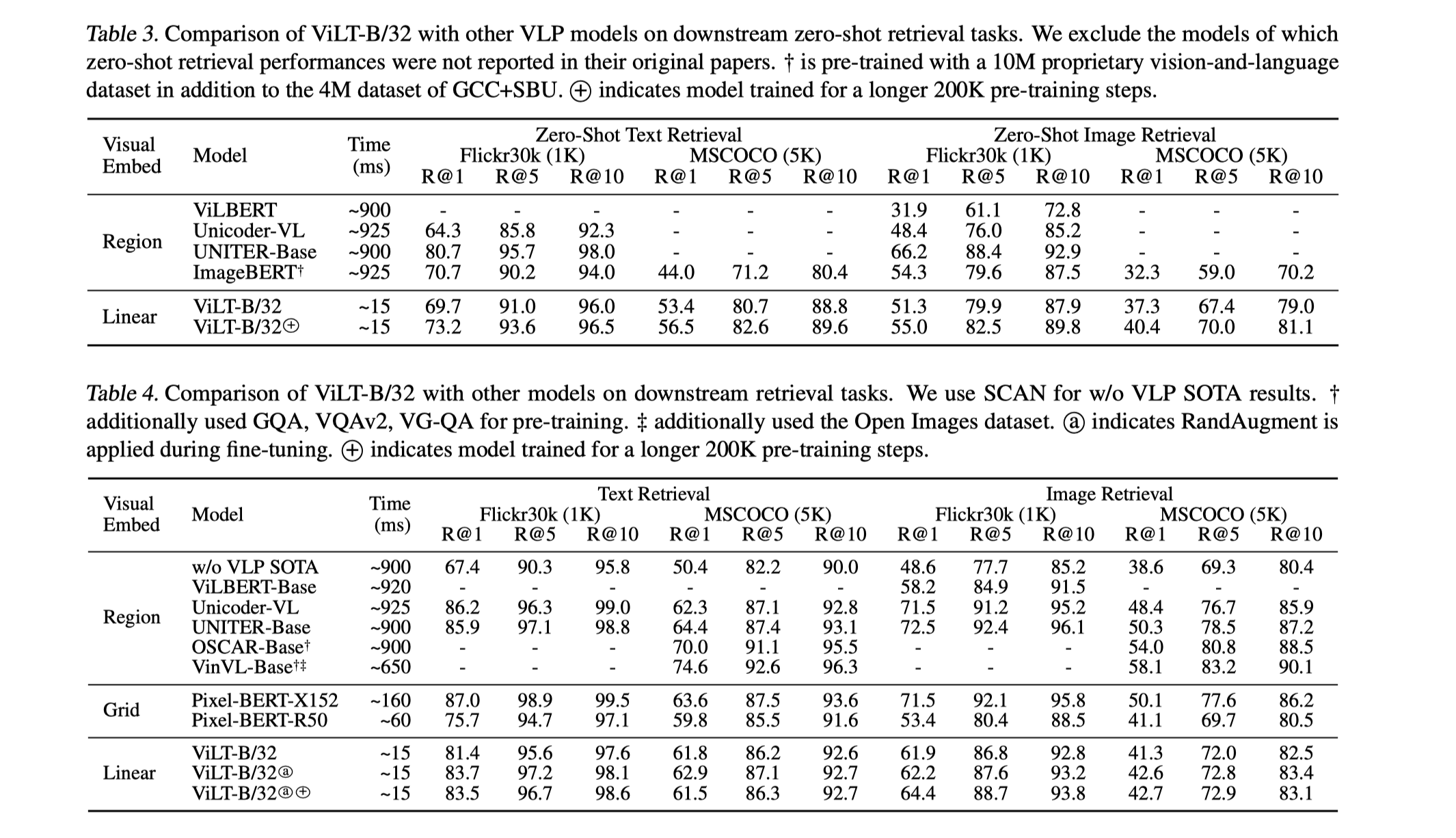
- 检索