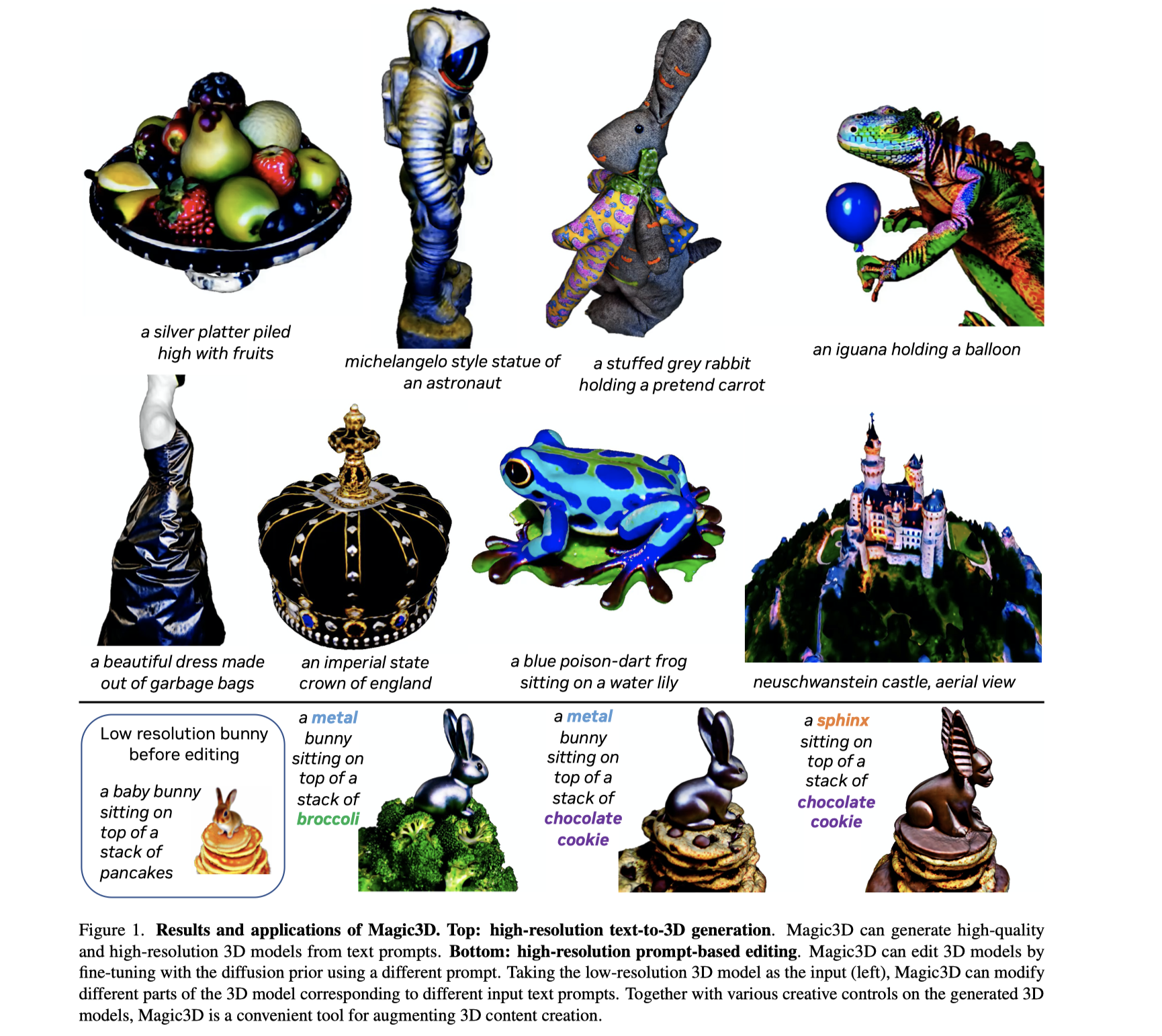
Magic3D: High-Resolution Text-to-3D Content Creation
TL;DR
DreamFusion 证明了用预训练的文生图diffusion 模型来优化nerf的能力,能够取得较好的text-3d 的结果。该方法存在两方面缺点(a)优化Nerf 速度慢 (b)Nerf上低分辨率优化,会生成低质量的3D模型。本文提出了两阶段方法。(1)使用低分辨率的diffusion prior来获得一个“粗糙”的3D Model, 同时用3D 稀疏哈希网格来进行加速。 将这个“粗糙”的表示作为初始化,接着优化一个带纹理的3D mesh model, 优化使用了和高分辨率latent diffusion 相互交互的可微分。该方法能够生成高质量3D hash model,在40分钟之内,相比Dreamfusion 方法有两倍加速,同时给用户提供了控制3D合成的方法。
Method
Background
- DreamFusion 模型包括两个关键部分:(1)场景模型(2)与训练好的text2img 的diffusion 模型。(a)场景模型是一个参数函数x = g(θ),可以在所需的相机姿态下产生图像x。这里,g是选择的体积渲染器,θ是一个坐标为基础的多层感知机(MLP),代表一个3D体积。(b)扩散模型ϕ配备了一个已学习的去噪函数ϵ ϕ (x t ; y, t),可以预测给定噪声图像x t、噪声级别t和文本嵌入y时采样的噪声ϵ。它提供了更新θ的梯度方向,使得所有渲染的图像在扩散先验下,都被推向由文本嵌入条件的高概率密度区域。
DreamFusion引入了得分蒸馏采样(Score Distillation Sampling, SDS),这个过程计算梯度:
$$
\nabla_{\theta} L_{SDS} \left( {\phi}, g(\theta) \right) = E_{t, \epsilon} \left[ w(t) \left( \epsilon_{\phi} (x_{t} ; y, t) - \epsilon \right)\frac{\partial x}{\partial \theta} \right]
$$
去噪函数ϵ ϕ通常被另一个使用无分类器指导(classifier-free guidance)的替代,这允许控制文本条件的强度
- 场景模型选择了带有显式阴影模型的Mip-NeRF 360的变种,并且使用ImageGen 作为扩散模型。这种模型只能在64x64分辨率上操作,无法获得高分辨率的纹理;另外,在大型全局MLP上进行体积渲染在计算和内存上都十分昂贵
High-Resolution 3D Generation
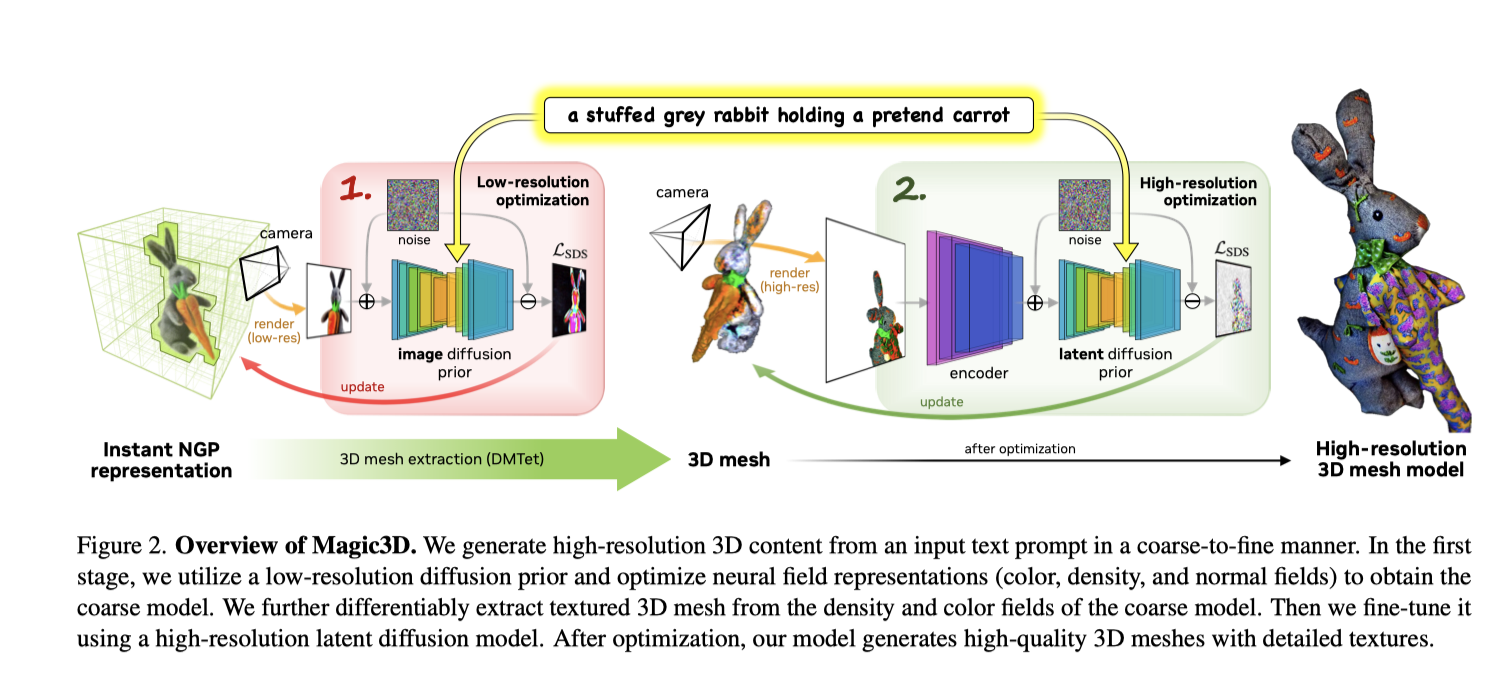
Coarse-to-fine Diffusion
- 第一阶段,使用了和Dream fusion 中类似的diffusion 模型,该diffusion 先验视用来计算场景模型的梯度,梯度更新依赖于低分辨率低rendered images
- 第二阶段:使用latent diffusion 在512x512上进行推理,这里使用了stable diffusion model。增加的计算时间主要来自于 $\partial x / \partial \theta$ (来自于高分辨率渲染图像的梯度), $\partial z / \partial x$ (encoder 的梯度)
Scene Models
- 粗糙优化阶段 : 选择了Instant NGP 中的hash grid encoding ,允许使用更低的计算成本表示高频细节。使用hash grid 和两个单层网络,一个预测反照率和密度,一个预测法线。使用来自Instant NGP的基于密度的体素修剪方法和基于八叉树的射线采样和渲染算法
- 精细优化阶段:使用带纹理的3D网格来作为精调阶段的场景表示。与为神经场进行体积渲染不同,对带纹理的网格进行可微分栅格化渲染可以在非常高的分辨率下有效地执行。使用coarse 阶段的神经场作为网格几何值的初始值。这里使用可变形的四面体网格($V_t$,T)来表示3D形状,其中$V_t$是网格T中的顶点。每个顶点$v_i$ ∈ $V_t$ ⊂ R 3 包含一个有符号距离场(SDF)值 $s_i$ ∈ R 和一个顶点从其初始规范坐标的变形 ∆$v_i$ ∈ R 3。然后,使用可微分的行走四面体算法从SDF中提取一个表面网格。对于纹理,使用神经颜色场作为体积纹理的representation。
Coarse-to-fine Optimzation
- Neural field optimization: 初始化一个占用率为256^3的网格(空间中哪些部分会被模型占用),模型周期性地更新这个网格,并使用一种技术叫做八叉树来跳过空的部分,以减少需要处理的计算量。
- MLP预测法线:不需要通过计算密度差来估计法线,这可以节省大量的计算资源
- 使用环境映射MLP模拟背景:为了更好地理解模型应该如何放置在3D场景中,建立一个背景模型。这个模型是用一个小的MLP来创建的,它可以预测光线方向对应的颜色。
- 网格优化:用一种叫做SDF(有符号距离场)的技术来表示的模型,然后使用一个叫做可微分光栅器的工具将我们的模型渲染成高分辨率的图像。再用高分辨率图像重新回去调整模型
- 增加焦距来展示细节
- 使用不同的抗锯齿技术来合成前景和背景
Experiment

- 去除掉背景之后,从图中可以看出Magic3D 方法纹理细节多了很多


Controllable 3D generation
- Personalized text to 3D: 代表性方法是dreambooth, 首先使用一些特定的图像(例如一只猫/ 一只狗的图片)来微调模型,然后在文本提示中加入一个特殊的标识(例如[V]),就可以根据文本提示来生成一个特定的3D模型。
- Prompt-based editing through fine-tuning:分为三个步骤:首先,使用一个prompt来训练一个coarse的模型;然后,改变prompt并使用LDM来对模型进行微调,这个步骤可以提供一个好的初始模型;最后,使用修改后的prompt来优化模型。这种方法在保持模型的基本结构的同时,改变模型的纹理或者形状。
