InstructPix2Pix: Learning to Follow Image Editing Instructions
TL;DR
本文提出的方法:在human instructions 和 给定图像,在指令指示下进行图像编辑。为了获取这个任务的训练数据,利用了GPT3(语言模型)和 Stable Diffusion (text2image)两个预训练模型的能力。Instruct pix2pix是 conditional stable diffusion. 由于无需对模型进行finetune 因此可以快速inference.

Method
- image editing 的训练还是看成一个 supervised learning 的问题。(1) 生成image editing instruction 和图像 (editing before / after )构建训练集 (2)用这个训练集训练 diffusion网络

Training Data Generation
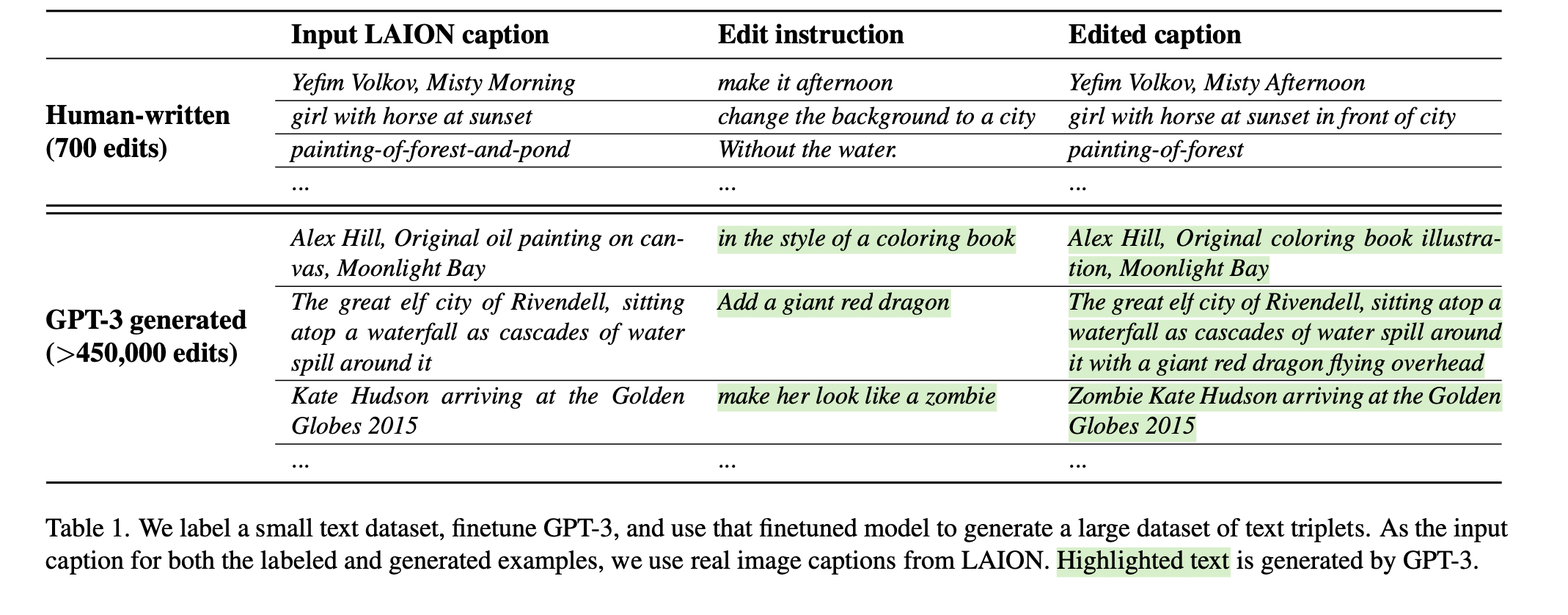
- a. 用GPT3 生成编辑的Caption
- b. 用Stable Diffusion& Prompt2Prompt 生成图像pair。Prompt2Prompt: 该方法旨在通过在一定数量的去噪步骤中借用交叉注意力权重,使得文本到图像扩散模型中的多个生成物相似。Prompt2Prompt 中有一个参数可以控制两个图像之间的相似度,作者认为仅仅根据标题和编辑文字确定这个值是困难。本文利用clip-based metric 来衡量两个图像之间的consistency,先随机生成100个图像,然后根据这个指标进行筛选。该度量标准衡量了图像对之间的变化在CLIP空间中与标题之间的变化的一致性,这有助于最大化图像对的多样性和质量
- c. 生成图像example
InstructPix2Pix
- 这里采用了一种改进的Diffusion Model —— Latent Diffusion, 它通过在pre-trained VAE 的latent space 中进行操作来提高扩散模型的数量和质量。
- latent diffusion 核心思想:将图像x 编码为潜在的latent 向量z, 然后在一系列的时间t 中逐渐增加噪声,产生潜在噪声变量z_t;为了预测在给定图像条件cI和文本指令条件cT下添加到噪声潜在变量zt的噪声,我们需要学习一个网络εθ。
- 这个模型的目标是最小化潜在扩散目标(Latent Diffusion Objective),这个目标计算了网络εθ预测的噪声(εθ(zt, t, E(cI), cT))与真实噪声ε之间的欧几里得距离(L2范数)的平方。
Classifier-free Guidance for two conditioning

- classifier-free diffusion guidance 常用于生成样本中质量和多样性之间的tradeoff。该方法常用于类条件和文本条件图像生成
- classifier-free 核心思想:本质是调整概率分布,将原始的概率分布进行转移,使得它更偏向于那些条件 c 高概率的数据。
- 训练时需要同时训练 「带条件」和「非条件」的去噪扩散模型。在推理时,则将两个预测分数进行合并。通过引导比例 s 和给定条件 c 来调整原始的概率分布,从而使得生成的数据样本更偏向于那些与条件 c 紧密相关的样本。
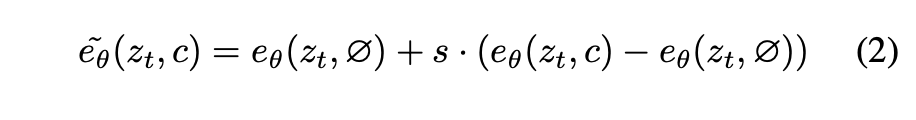
- 在训练中,随机将5%的图像置为空,随机将5%的文本置为空,也同时把5%的文本和图像同时置为空。本人无的score network 包括两个条件,因此也要引入两个condition scale。
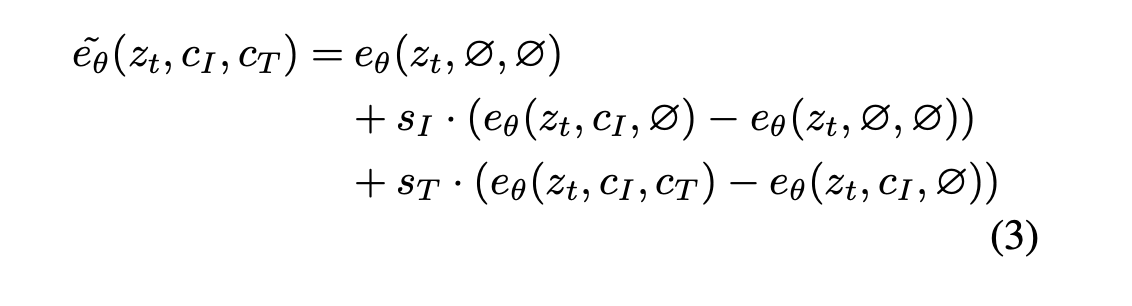
Experiment

Baseline Comparison
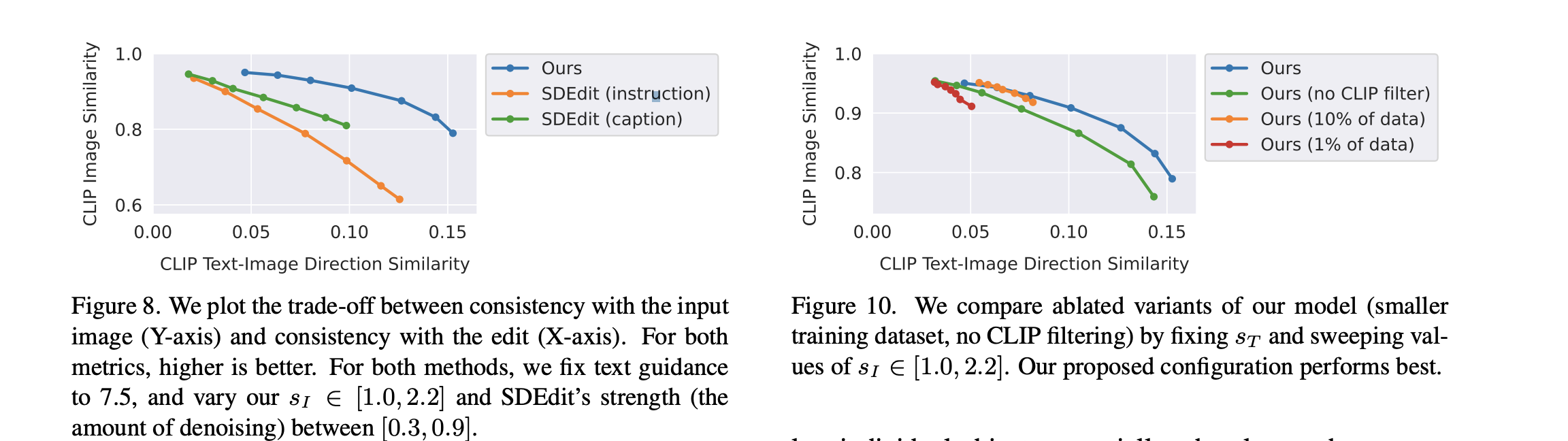
- SDEdit 和 Text2Live上做测评。text2live,指在文字prompt的提示下, 做透明和颜色的增广。从图中可以看出,这个问题难点是在保护ID和孤立物体,特别是当需要比较大范围的变化时。
- direction similarity: 衡量图像和文本变化一致性度量。方法是先获得两两text embed, 两两图像embed 之间的变化方向,然后计算他们的cosine距离。值也是越高越好。
- clip image similarity 跟 direction similarity之间是相互tradeoff的。

Ablation
- 当减少数据集数量,模型做large edit 的能力显著降低(更大范围的变化),模型仅仅会在风格上做微小的调整。在指标上就是,图像的一致性很高,但是direction 相似度很低。
- Clip filtering 去掉后,输出图像和输入图像的一致性显著降低。