Towards Robust Blind Face Restoration with Codebook Lookup Transformer
TL;DR
Blind face restoration 有两个挑战。(1)改善从降质输入到对应输出的映射(2)对输入进行高质量的细节补偿。本文把盲人脸恢复转变为码本预测任务,证明了在一个代理空间中用可学的codebook可以显著减少该任务的不确定性和歧义。文章提出Codeformer, 是一种transformer-based 的结构用于建模人脸的全局组成和上下文。
Code:https://github.com/sczhou/CodeFormer
Motivation
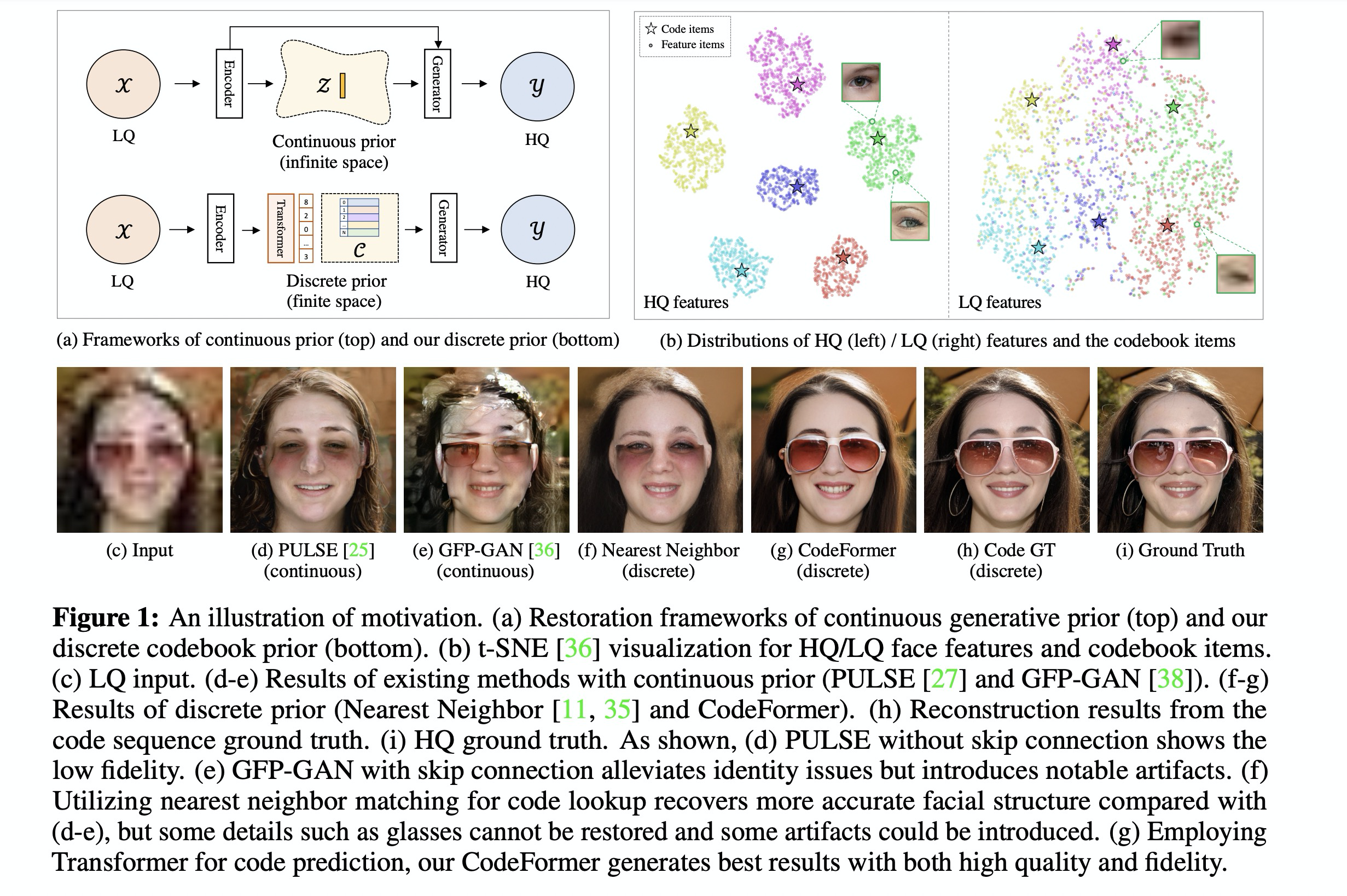
- (a) 上图表示连续的生成式先验,下图表示码本先验。(b)t-sne 可视化对高清 / 低清图像进行可视化操作 (d/e)是前者的典型代表,(f/g)则是离散码本。
Methodology
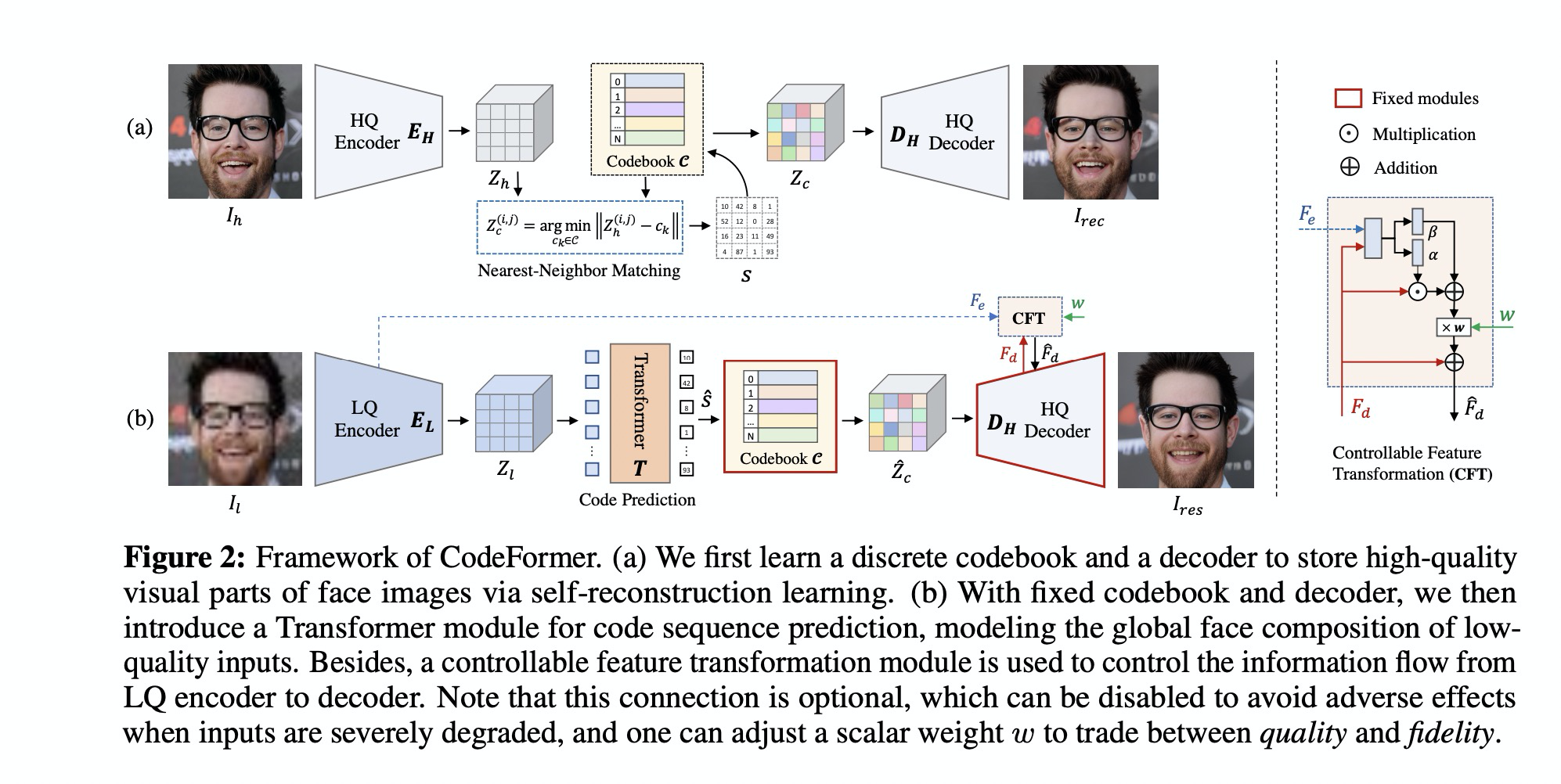
- (a) 第一阶段学习离散的码本和decoder来恢复高质量图像 (2)把码本/ decoder固定住,引入Transformer 模块来对码本序列进行预测。同时引入一个可控模块来调节从LQ encoder 来的信息流,主要目的是在恢复程度和保真度之间做一个trade-off
Codebook Learning Stage I
- pre-train 一个向量量化的auto-encoder,从而获得一个高质量的码本。可以保持网络的有效性同时也提升鲁棒程度
- 一个H x W x 3的高清图像被编码成 m x n x d 的压缩编码Zh。Zh中的每个像素被替换成码本中最近的一个子项,从而获得quantized feature 和对应码本的token 序列

- 训练带codebook 的auto encoder 用了三种loss。l1 / perceptual loss / adv loss ; 同时也用了code-level loss, 减少codebook 和 embed feature 之间的距离

- Codebook 的压缩倍率是32。子项的数量被设为1024
Codebook Lookup Transformer Learning II
- 为了解决最近邻match 失败的问题,引入Transformer;包含9个self-attention block 。将Codebook / Decoder 固定住,然后去finetune encoder. 首先将Feature 展开成(mn)d,接着送给Transformer block. 最终预测出 (mn)的序列

- 既训练Transformer,同时也训练Encoder。(1)cross-entropy loss for code token (2)l2 loss 拉近 El 和 Code之间的距离
Controllable Feature Transformation Stage III
- alpha / beta,是输入Fe,Fd. CFT模块作用在encoder / decoder feature 之间的4个尺度。在训练过程中除了维持stage2 的tf loss, 还用上stage 1 的image level loss。

Experiment
- 训练集合 FFHQ + 降质
- 设置上用 16X16的code 代替512 X 512的图像。batchsize 16,lr 一阶段 8e-5;4块V100

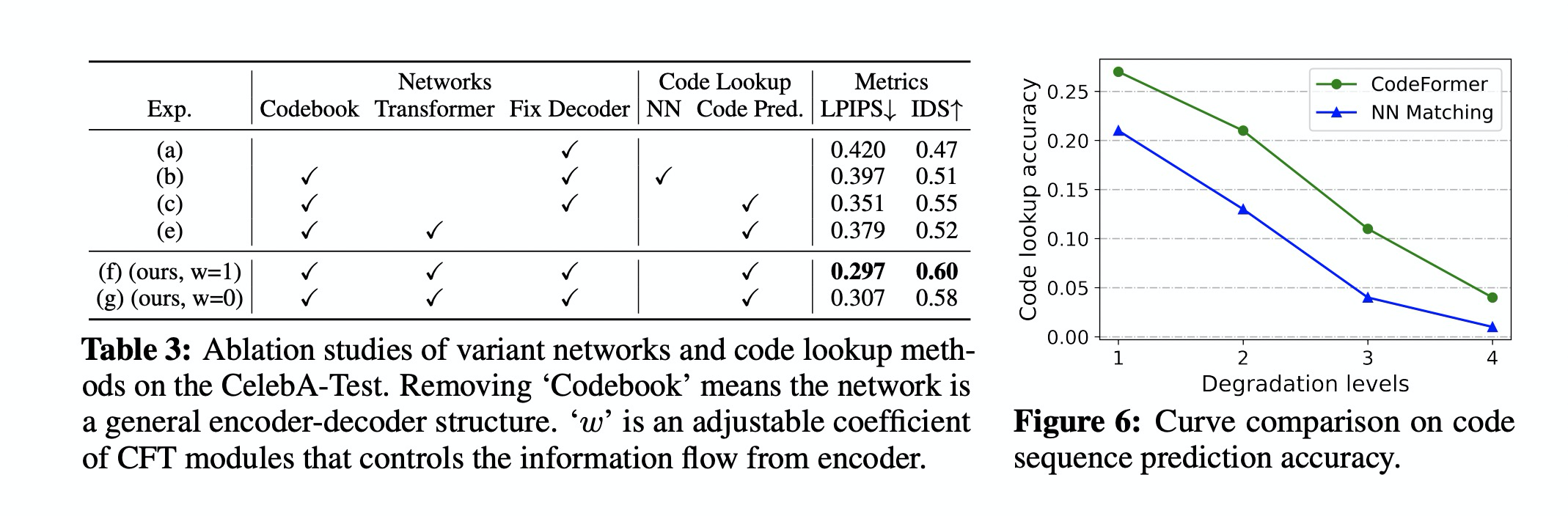
- Ablation Study
- wo-codebook 就是标准的encoder / decoder 。CNN based 方法在序列预测上表现不如Transformer
- fixed decoder 是重要的。