MaskGIT: Masked Generative Image Transformer
TL;DR
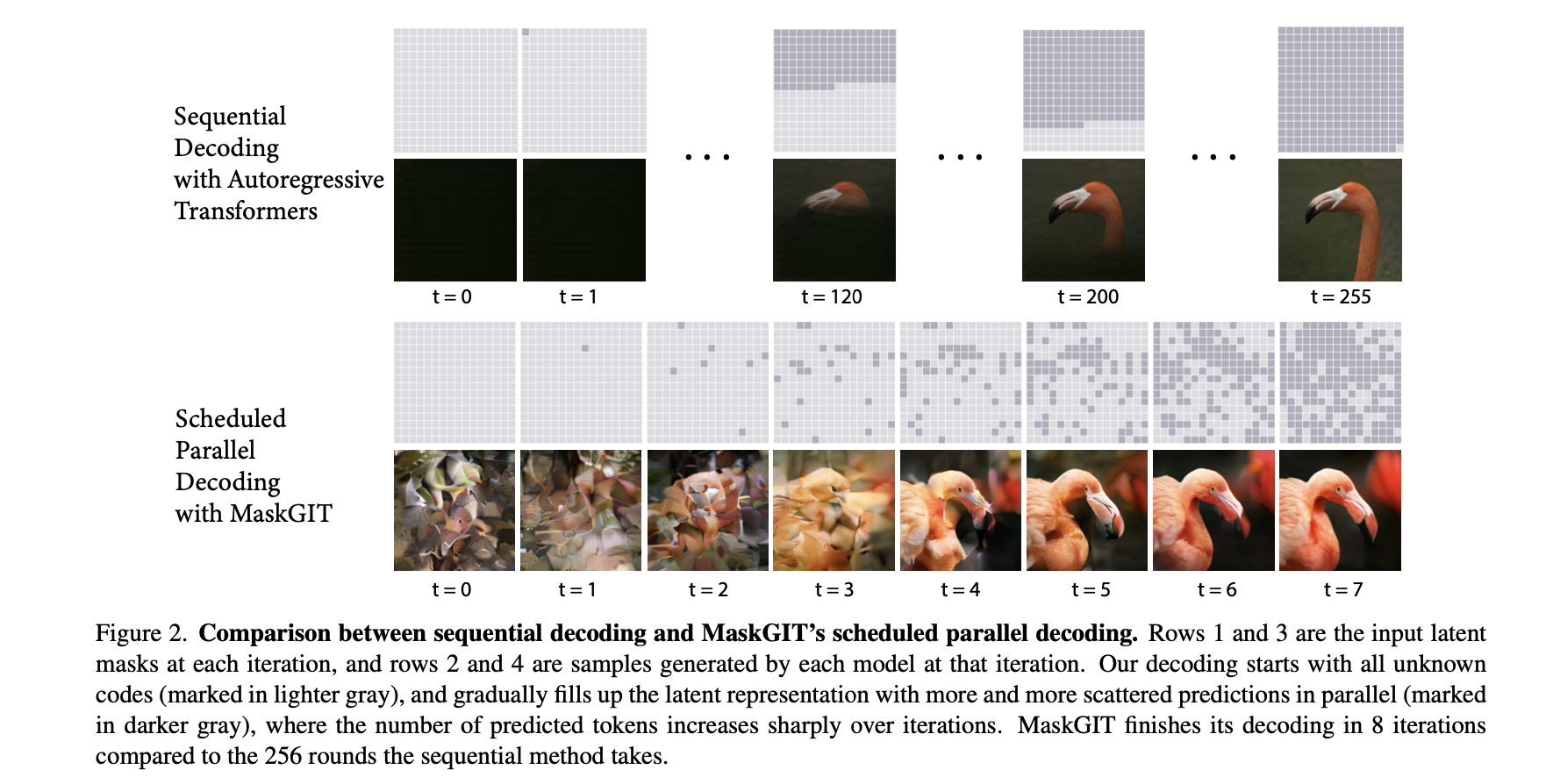
在此之前,最好的transformer 模型做法是把图像先编码成token 序列,然后line-by-line 的进行解码,作者认为这种方式不是最优也不是最高效的。本文提出MaskGIT, 一种的图像合成领域的新范式,使用一种双向的transformer decoder. 在训练阶段,MaskGIT从所有方向上实行attention机制,从而预测随机masked token。在推理阶段,模型先同步生成图像的所有token,然后不断refine之前生成的结果。该方法相比之前的AR方法,有64x 的加速。
Method
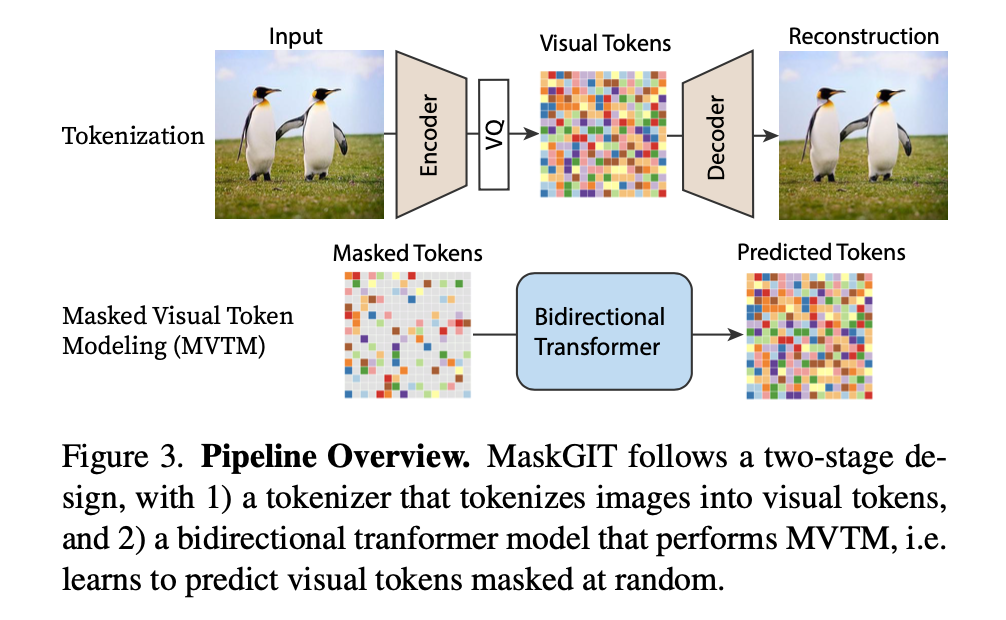
- MaskGit 的目标是提升二阶段的效果,一阶段和VQGAN方法保持一致
3.1 Masked Visual Token Modeling(MVTM)
- $Y = [{y_i}]_{i=1}^N$ 把图像输入VQ Encoder,获得的latent tokens。 N表示把token matix reshape 后的矩阵长度。
- $M=[{m_i}]_{i=1}^N$ 表示对应的binary mask
- 在训练过程中,获得的latent token 被【Mask】token随机替换。采样过程是首先从0,1之间的均匀分布采样出一个ratio的值。然后从N个token 中采样出 $[\gamma * N]$ 个token
- $Y_{\overline M}$ 表示把Mask apply 到token Y上

Iterative Decoding
图像压缩得到的所有token可以并行被decoder,这是提出的双向 self-attention所带来的feature。每个算法迭代,可以分为如下几个步骤
- predict:在第t 次迭代,给定masked token,模型输出所有掩模位置的概率分布 - $p^{(t)} \in R^{N \times K}$
- sample :对于每个mask 位置,根据codebook中的所有token的概率分布进行
- mask schedule:根据上述的mask schedule function 来确定采样token 的单位
- mask
$$
m_{i}^{t+1} = \begin{cases}
1, & \text{if } c_i \geq \operatorname*{sorted}_{j} (c_j)[n] \
0, & \text{otherwise}
\end{cases}
$$- 简单描述decoder过程,模型同时预测出所有的token,并且只保留置信度最高的一项。剩余的token 会被mask住并且重新预测。mask ratio逐步减小,直到T次迭代生成所有的token为止。
Mask Design
- masking design对生成图像的质量影响很大,因此mask schedule function 很关键。在测试阶段,mask ratio 分别为 $0/T,1/T, …… ,(T-1)/T$ ti
- 提出一种新的mask schedule function,首先从性质上它必须是有界且连续,其次要单调递减。这里分别分成了三个组的function来表示这些函数。• Linear / • Concave / Convex 。后面有实验会比较
Experiment
- Settings:
- (1)One encoder / one decoder for each dataset, 1024 token codebook. 图像尺寸256x256。这个token 尺寸在512 x 512上的图也是适用的。
- (2)24 layer, 8 attention head, 768 embed dimensions, 3072 hidden dimensions.
- 相比BigGAN而言效果提升不少
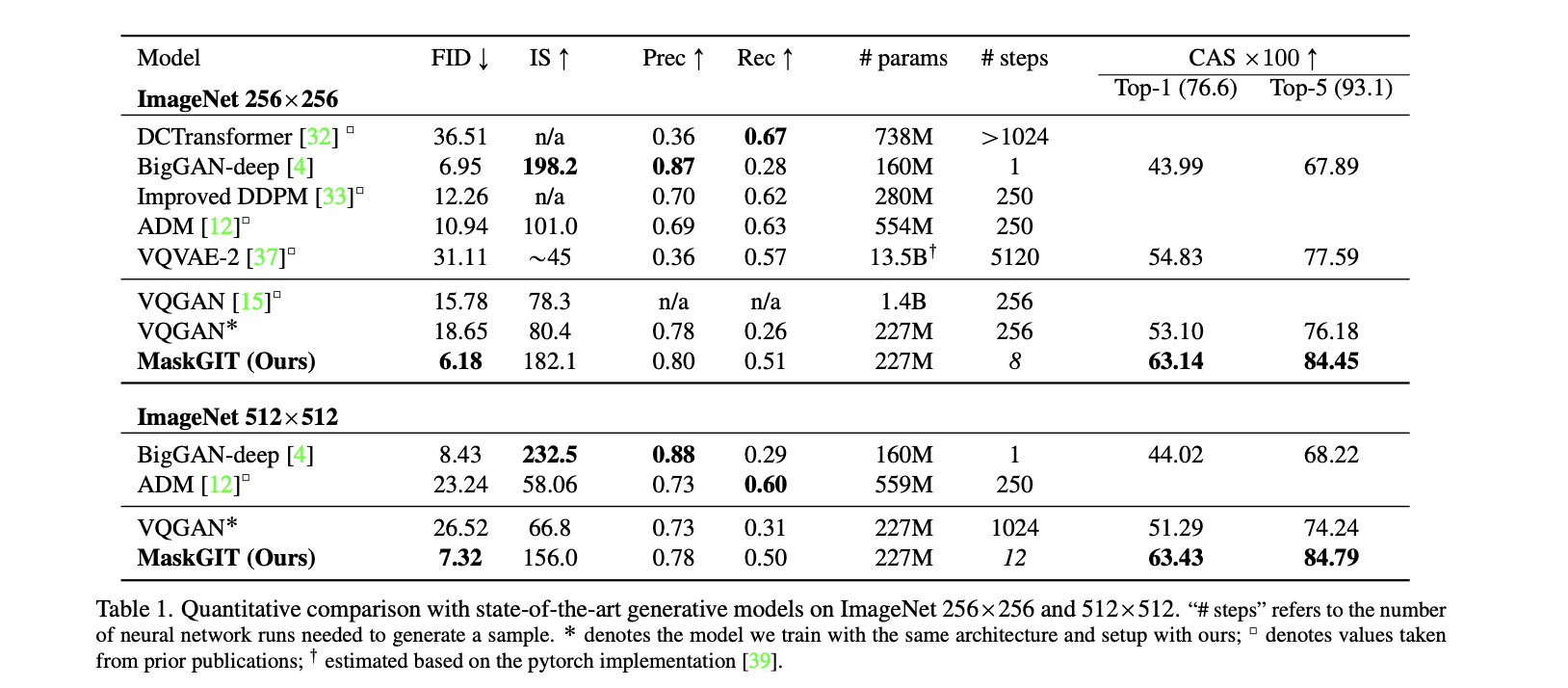

Image Editing
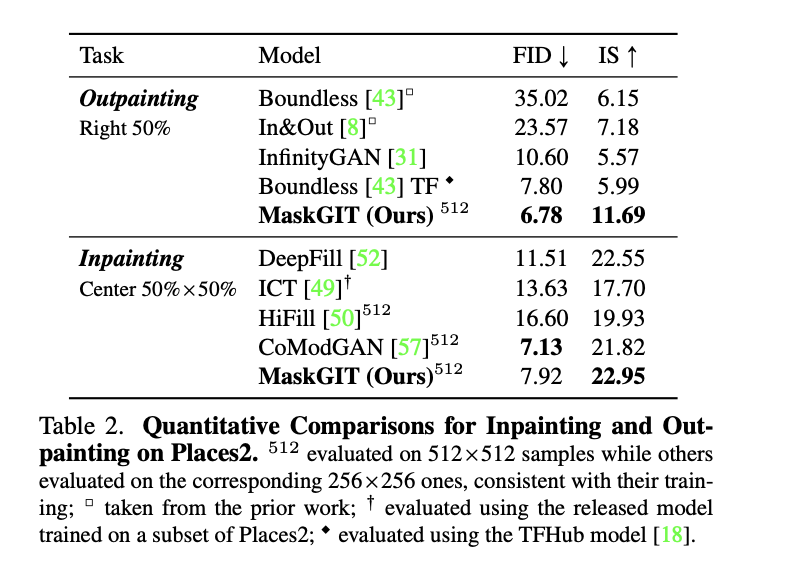
- 一些 inpainting / outpainting的应用

Thoughts
有限次数去逐渐decoder token, 替代了line-by-line的方式。