Neural Discrete Representation Learning
TL;DR
无监督情况下获取有用Representations 很有挑战,本文提出一种生成式模型来提取离散的representation. Vector Quantised- Variational AutoEncoder (VQ-VAE) 和 VAE 主要有两点不同:(1)encoder输出离散的codes(2)prior是学来的不是静态的。使用VQ方法能够让模型比较好的绕过「后向坍塌」问题
Method
VAE主要包括以下几个部分:(1)编码器,参数化成一个后验概率分布q(z|x), x为给定的输入分量,其中z为离散潜在随机变量;(2)一个先验概率分布p(z),(3)带有输入分量p(x|z)分布的解码器。
Discrete Latent variables
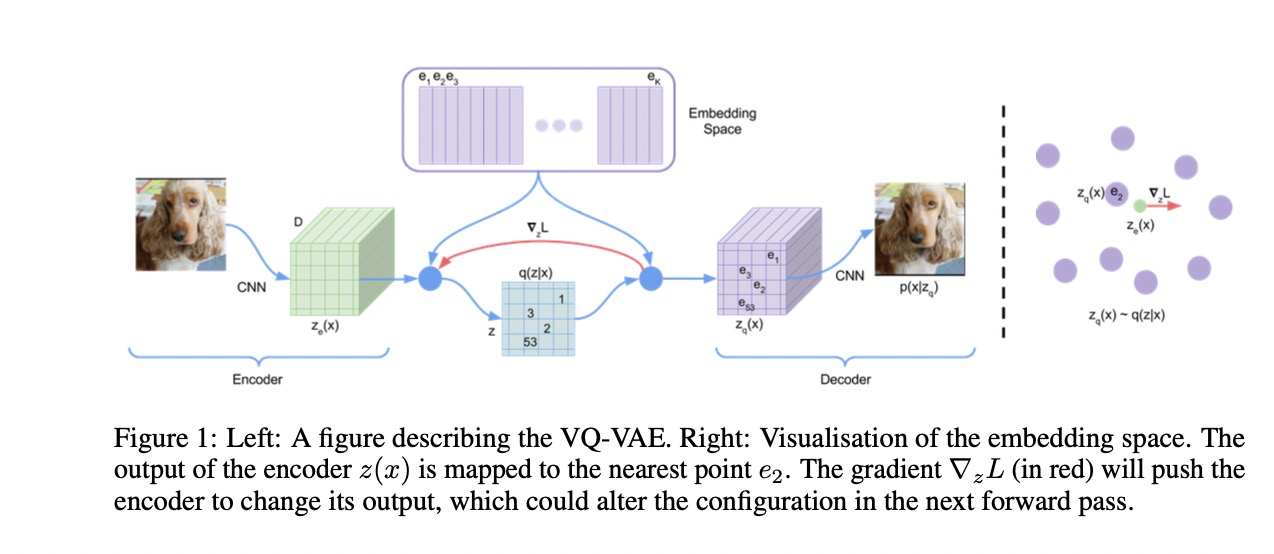
首先定义了一个潜在的embed 空间,空间的大小表示为K x D; K 则是种类,D是每个embedding vector的长度。给定输入x, 把它送给编码器得到 z_e(x), 然后在embedding 空间中用最近邻的方法进行搜索,得到离散潜在的变量z. 该模型的所有参数包括编码器 / 解码器 / embedding 空间的参数。

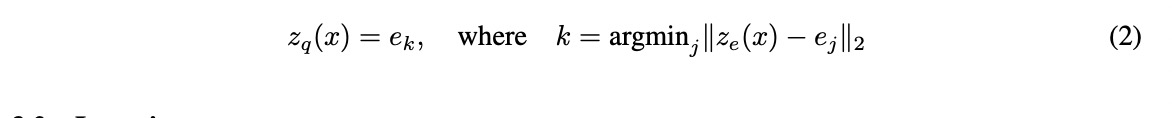
在语音 / 图像 / 视频上,每个vector的分别为 1D / 2D / 3D
Learning
上述公式2中的梯度并没有定义,于是采用STE来近似得到梯度。或者将解码器的输入的梯度替换到编码器输出的梯度上。论文这里表示都可以,取决于使用场景。
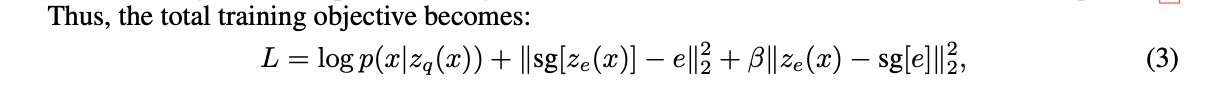
损失函数主要分为几个部分,reconstruct loss(data term)优化编码器和解码器;在这个过程中由于STE的存在,embedding space 部分是没有梯度的。embedding 空间的优化采用向量优化的算法,VQ项用l2 loss 来使得embeding 与编码器输出相靠齐。
- sg 表示stop gradient操作。 forward 是 identity。
Prior
在图像任务上,使用Pixel CNN, 语音任务上用WaveNet
Experiment
- Comparison with continuous variables
和连续的隐变量做对比的实验,对比了普通的VAE,VIMCO(独立高斯 / 分类先验)和 VQ-VAE。VAE、VQ-VAE和VIMCO模型的比特/维度(bits/dim)分别为4.51、4.67和5.14。说明结果是相当的。
- Images
图像上大部分的信息是冗余且带噪,实验中将128X128图像压缩至32X32 的隐空间中,压缩了大约42倍,但是重建的图像有些blur


- Video
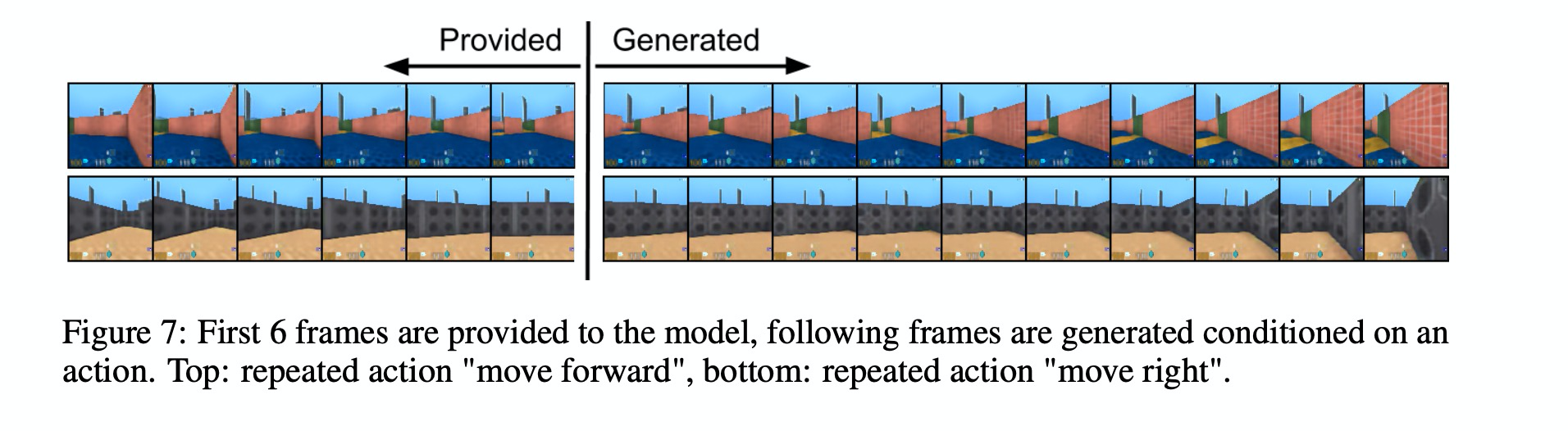
给定前几帧和动作,生成后续帧。