TL;DR
CNN方案有如下缺陷:limited receptive field, 随着高分辨率暴增的算力。本文提出 Restormer - Restoration Transformer, 在去雨,去噪,去模糊任务上取得了不错的效果
Method
目标是设计一种efficient transformer 来处理高分辨率图像的图像复原任务。Key Design: Multi-head SA layer & multi-scale hierarchical, 相比single - scale 的网络可以显著减少计算量。
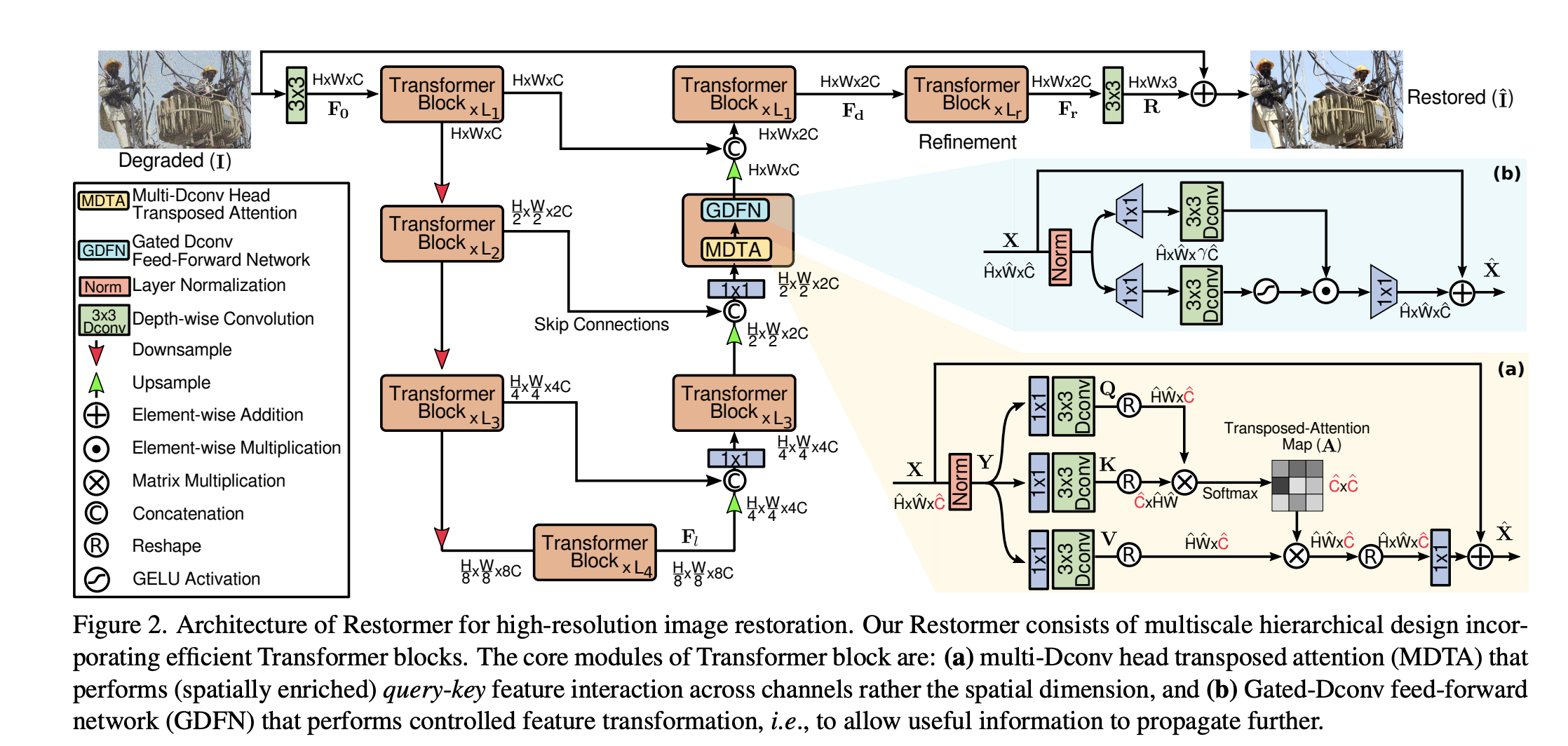
Multi-Dconv Head Transposed Attention
- 主要开销来自于self-attention layer,其中key-query dot- product interaction 随着分辨率的增大而增大,为$O(W^2H^2)$。 因此,本文提出MDTA模块,复杂度是线性的。主要做法是self-attention 作用在channel上而不是空间分辨率上,channel 上产生的是global context,因此又同时引入了depth-wise conv来增强local context,这里用的conv都是不带bias的。

Gated-Dconv Feed-Forward Network
- 常规的transformer 前向网络: 1X1 扩大channel数,减少回原始channel数。
- 本文做法:(1)引入gate机制 (2)可分离卷积。 将输入分为两路,每路是1X1 + 3X3 D-conv,其中一路使用GRelu作为激活函数
Progressive Learning
- 传统训练方法:从CNN中crop 一个小patch,然后进行训练
- 在early epoch使用小patch训练,然后逐步增大训练图像的尺寸。类似不断用大尺寸finetune。这样的好处使得transformer可以encoder整个大图的feature。训练过程中尺寸变大,batchsize也相应变小,从而维持相同的训练时间