TL;DR
这篇论文介绍了一种新的生成模型的范式,称为“Composer”,该范式可以在保持合成质量和模型创造力的同时,灵活地控制输出图像,如空间布局(layout)和调色板(platte)。该模型的核心思想是分解图像为代表性的factor,并使用所有这些factor作为条件来训练扩散模型以重新组合输入。在推理阶段,由于中间表示丰富,从而可以产生巨大的生成设计空间。该方法支持各种级别的条件,例如文本描述作为全局信息,深度图和草图作为局部指导,颜色直方图用于低级细节等。除了改善可控性外,该方法还证实了作为通用框架的优势,可以方便地支持各种经典生成任务而无需重新训练。
Method

- Composer是一种扩散模型,可接受多个条件,从而实现无分类器指导的各种方向.
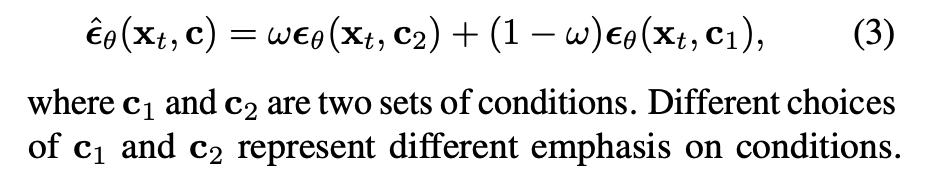
- 通过指定一个权重参数 ω 来控制这些条件。属于 c2 但不属于 c1 的条件会被赋予权重 ω,属于 c1 但不属于 c2 的条件会被赋予权重 (1-ω),而属于 c1 与 c2 的交集的条件会被赋予权重 1.0
- 通过对图像x0进行反向编码,得到其潜在表示xT,然后使用另一个条件c2对xT进行采样,可以以一种解耦的方式操纵图像,其中操纵方向由c2和c1之间的差异定义。

Decomposition
将图像分为8个方面,每个方面都可以在训练中动态提取。
- Caption:直接使用文本-图像的训练数据,或者从预训练的模型中获得。
- Semantics and style
- Color:CIELab histogram
- Sketch
- Instance: Yolov5
- Depthmap
- Intensity: 灰度图
- Masking:ROI区域

Composition
- 全局化条件:including CLIP sentence embeddings, image embeddings and color palettes
- 局部化条件:sketches、segmentation masks、depthmaps、intensity images和masked images等本地表示,将它们投影到与噪声潜变量xt相同空间大小的统一维度嵌入中,使用堆叠的卷积层进行处理。然后计算这些嵌入的总和,并将结果连接到xt之前,将其送到UNet中
- 联合训练:在每个条件的训练采取类似dropout的策略