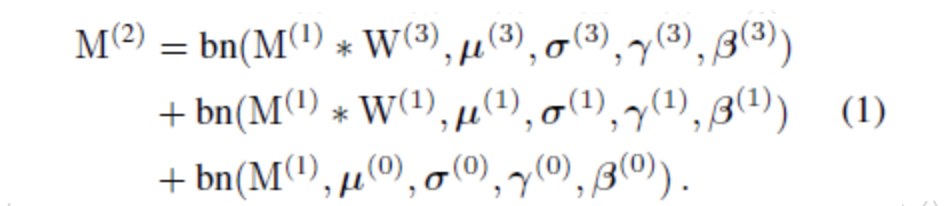TL;DR
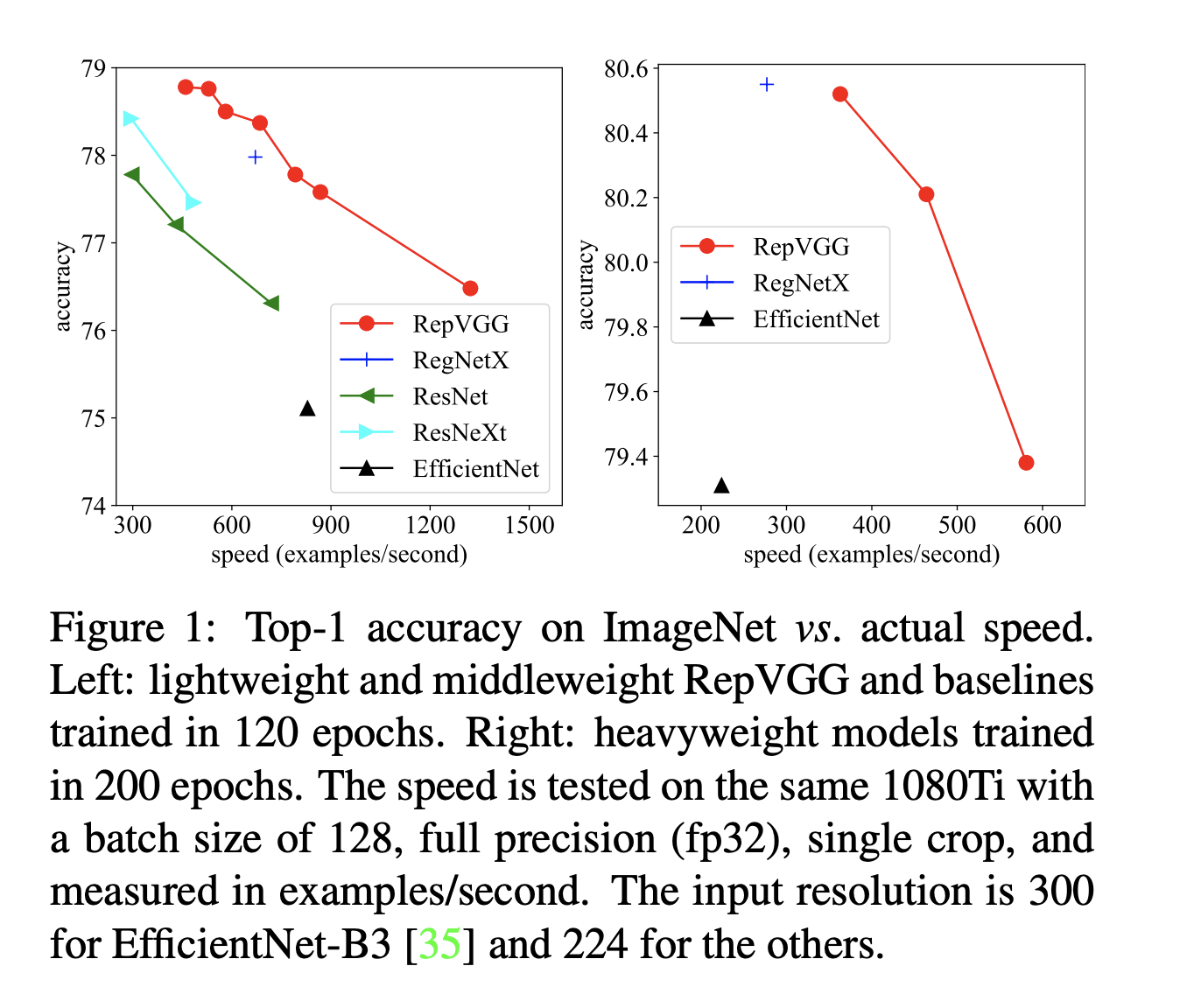
本文提出了一个结构简单但功能强大的卷积神经网络架构,该结构在推理时候具有类似于VGG的backbone,仅由3 x 3 conv和ReLU堆叠组成。但在训练时,它却有着多分支的拓扑结构,它通过重参数化技术实现了训练和推理方面的解耦,因此该模型被称作Rep-VGG. RepVGG 在Image Net 上的top-1 准确率超过了80%,在NVIDIA 1080Ti 上推理速度更快,远快于ResNet-50 / 100 。与新模型相比,也展现了比较好的速度 / 准确率的trade-off
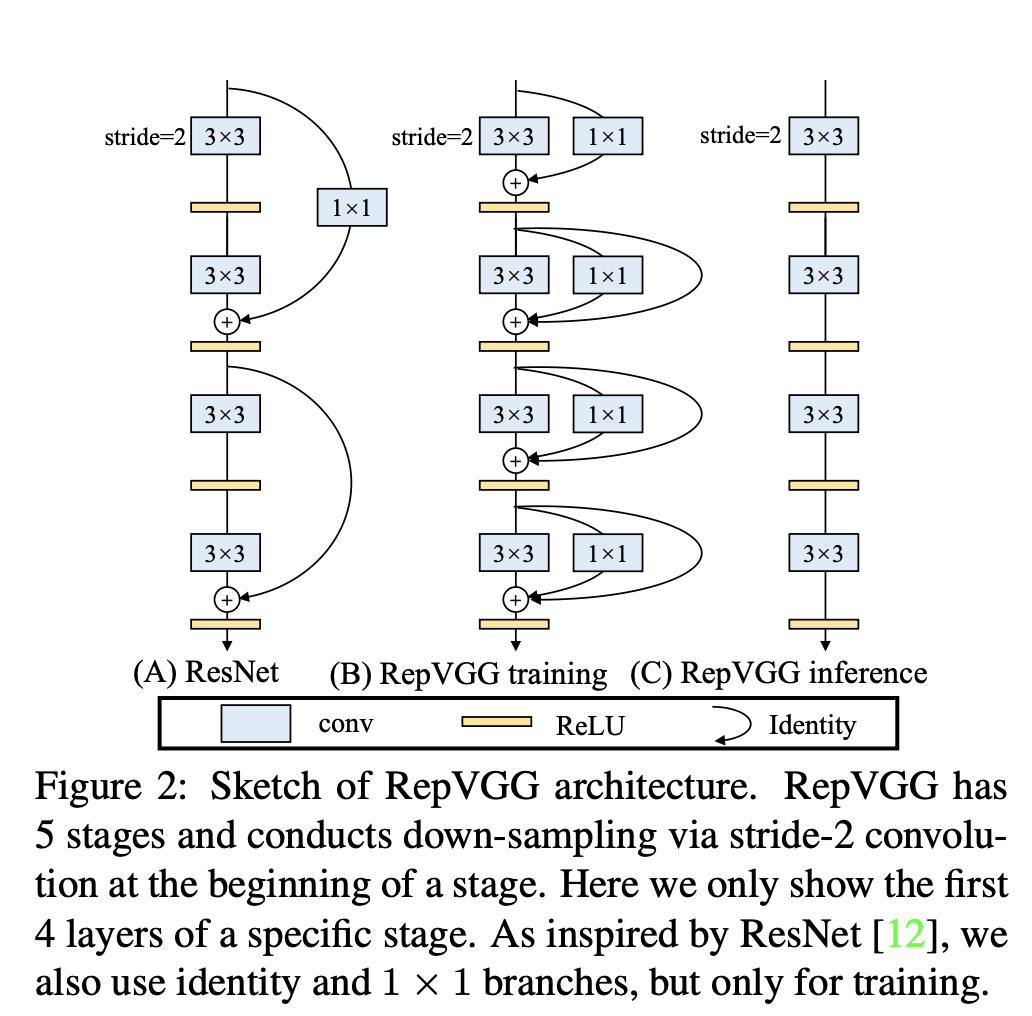
上图展示的是训练和测试如何实现解耦,中间部分为训练中网络结构,吸收了ResNet 的优点
Method
Simple is Fast, Memory-economical, Flexible
- 有两个因素会导致Flops和速度之间的Gap: MAC 和 并行度。在相同的FLOPs下,具有高并行度的模型可能比具有低并行度的模型快得多。堆叠结构拥有更高的并行度。
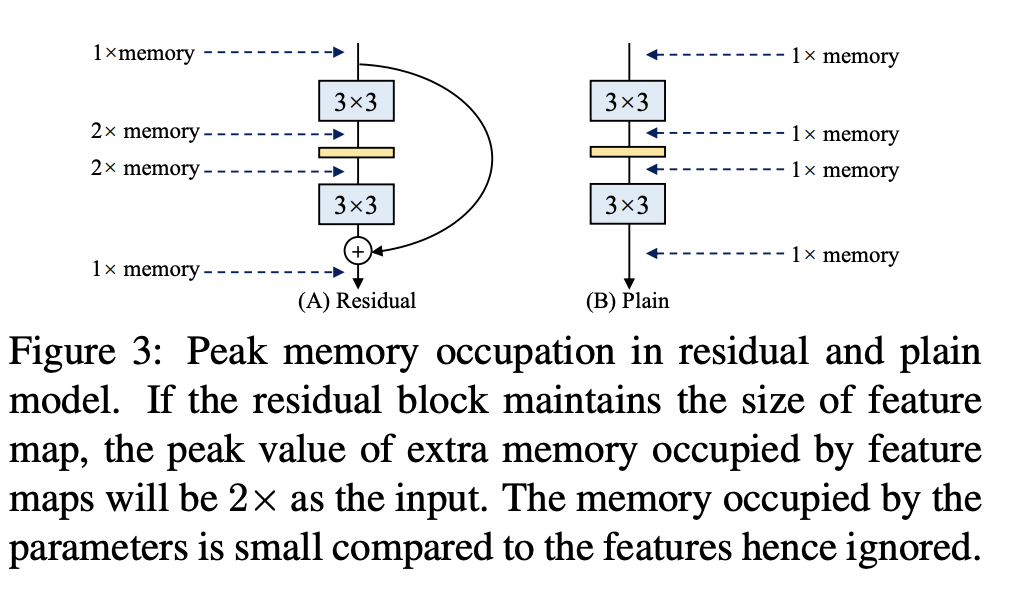
- 多分支拓扑结构由于需要保留每个分支的结果,直到相加或串联为止,分支中的特征图尺寸保持不变时,需要两倍的内存。
- 在简单的堆叠结构中,允许计算完改层后立即释放该层的输入所占用的内存。因此这种计算方式也对硬件更加友好。
- 多分支结构也会造成剪枝上的困难
.Re-param for Plain Inference-time Model
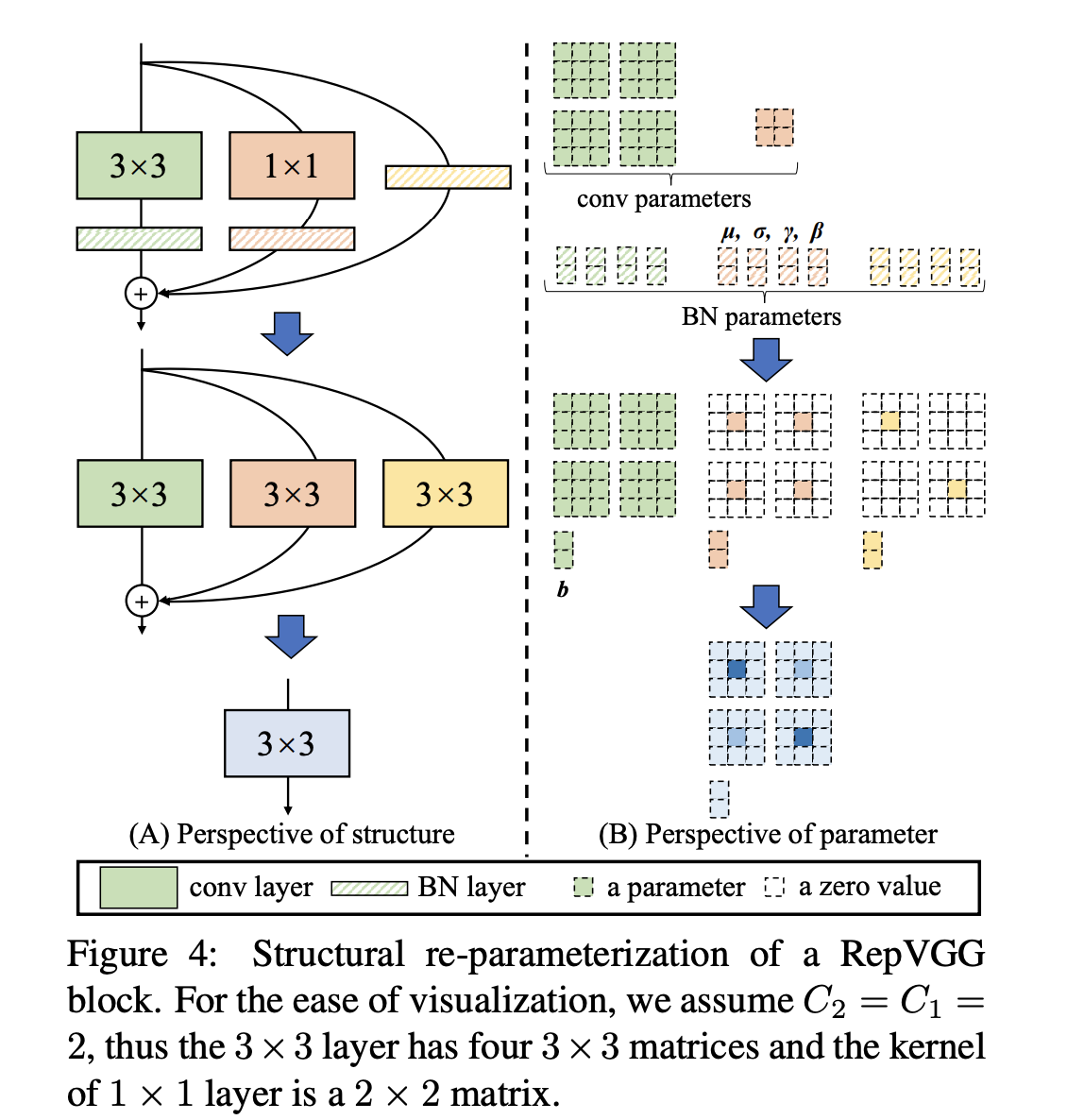
- 如果大kernel 卷积和小kernel 卷积的步长相同,那么就可以用简单叠加的方法合多个分支的卷积核,用单个卷积来替代,小kernel卷积通过补零的方式padding成大卷积的尺寸
- 对于3x3的图层,将输入填充一个像素,则1 x 1的图层应具有padding = 0
- 总结起来一共两步变化:把所有卷积变化成3X3,紧接着把多分支合并成一个。
- 对BN参数进行融合