Attentive Fine-Grained Structured Sparsity for Image Restoration
TL;DR
N:M structured pruning 是目前比较有效的模型压缩技术,本文提出了对每一层实现不同的sturtured sparsity的pruning方法,进而实现准确性和效率之间的tradeoff
Method
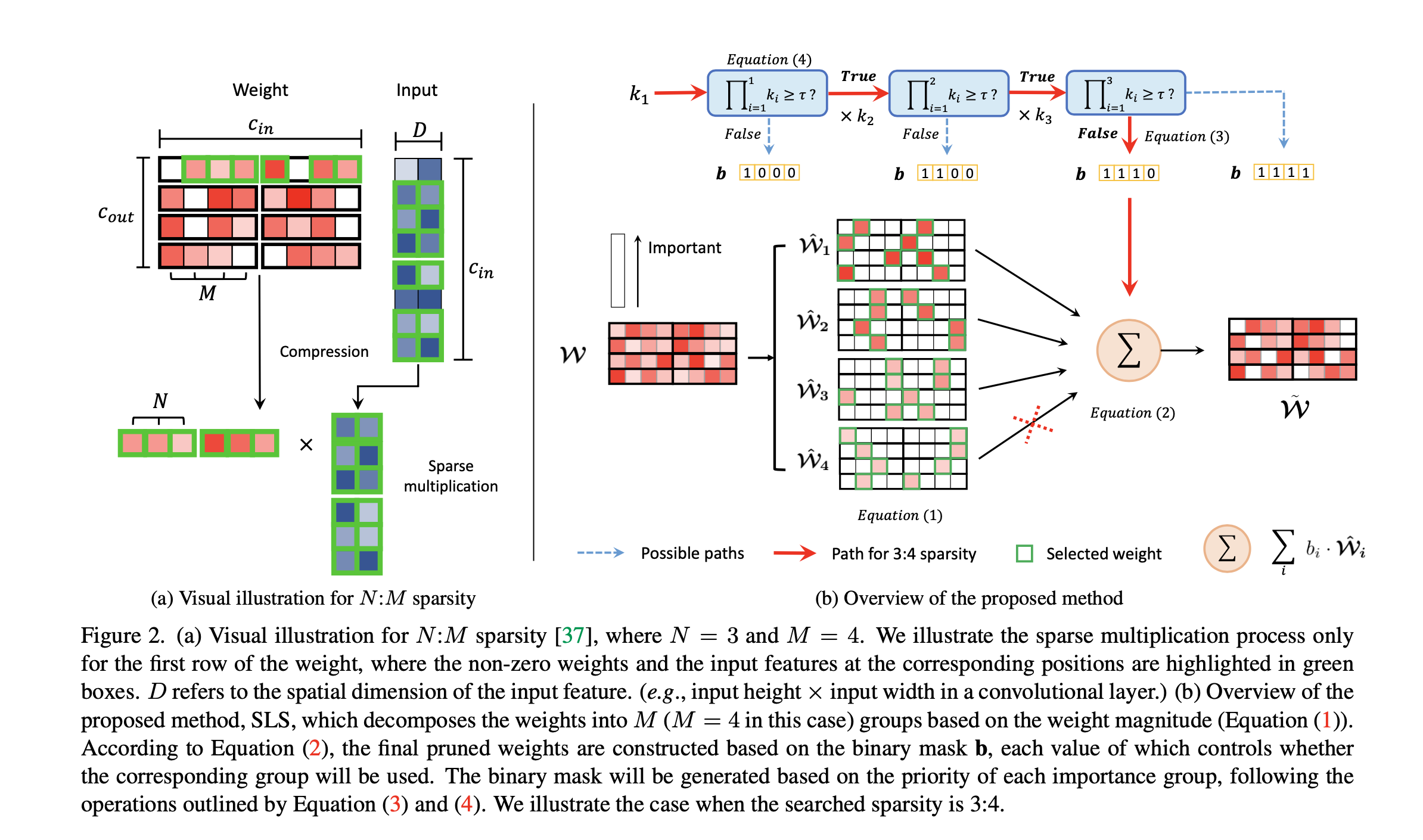
一个满足N:M sparsity的tensor应该满足如下性质。(1)input channel 可以被M整除 (2)每组M个连续weights至少有N个非零权重。weight,input tensor的压缩方法如图(a)所示。两者都能有N:M的压缩空间
可导的N:M Sparsity Search
- 首先将weight表示为M组 1:M sparisity的稀疏weight之和。每一个weight的重要性都用 一个强度参数来衡量
- b是一个二值参数,表示该组参数是否被保留还是丢弃,梯度下降中通过STE来优化这个值. B 中p表示weight的优先级分数,用于决定pruning ratio

Priority - Ordered Pruning
- 上述一共有两种度量方式来决定pruning ratio。当两者产生mis alignment时,容易造成性能下降。通过使得Pi+i < Pi, 优先移除强度参数小的权重


Loss Function
pruned Loss 表示压缩后模型的MACS,通过如下形式实现算法性能和模型大小之间的tradeoff

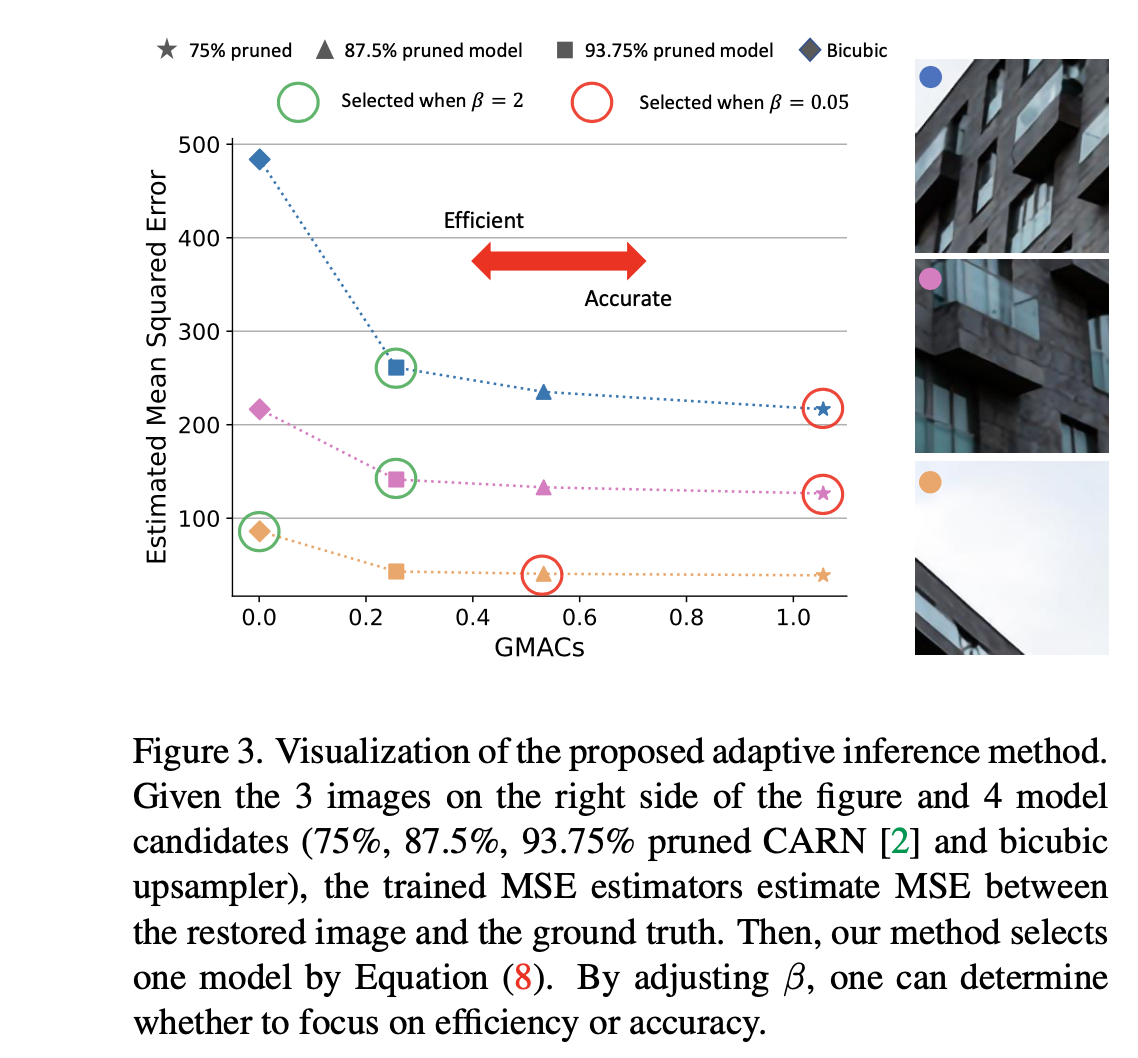
Adaptive Inference
- 通过图像patch的难度,来自适应使用剪枝模型。为了量化图像块的恢复难度,假设图像块越难恢复,GT与恢复结果之间的误差越大。由于在推理时无法获得GT,我们使用了一种轻型卷积神经网络,可以估计GT和目标模型恢复结果之间的均方误差(MSE)。给定由具有不同目标计算预算的SLS训练的多个模型,来给候选模型来打分。