Accelerating Video Object Segmentation with Compressed Video
TL;DR
提供了一种高效的,即插即用的加速框架,用于解决半监督点视频物体分割任务。如何加速,利用视频序列的冗余程度以及压缩比特流。为了实现把 关键帧的mask 单向/双向传播给其他帧。另外还设计了residual-based correction module 来fix 错误的mask。
Preliminaries
- HEVC coding structure包括一系列帧称为(GOP),每个GOP使用三种帧类型:I-frame / P-frame / B-frame. I frame表示完全独立地被编码。P-frame / B-frame 则表示通过来自其他帧的运动补偿和残差来编码。P / B frame 存储的motion vector可以被认为是block-wise 的光流。
- Motion compensation in compressed video
- 预测motion vector 的模块被称为PU。Prediction Unit,size 可以是64X64, 8X4, 4X4.
- PU可以是单向的,也可以双向。P-frame 只包含单向的PU,B-frame 包括双向PU
- 通过双向的motion vector,可以通过线性组合来重构帧。

- 在一些比较旧的编码设置中,例如CVOS,reference 帧的选择也有要求,必须是I-frame。现代Codec方法,允许P-frame,B-frame类型,从其他的 P / B中去获取参考的pixel . 由于Motion Vector比较粗糙,因此也沿用了一个 Residue对恢复的图像进行pixel detail的修复
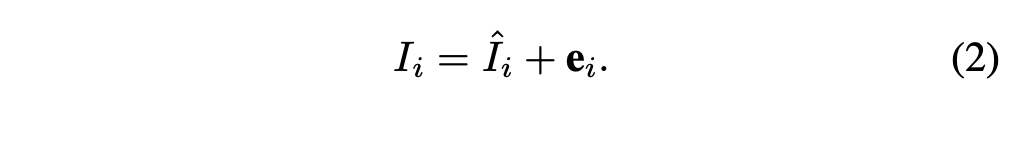
- E_i 应当是稀疏的,E_i 的稀疏程度和PU的准确程度成正比
Method
问题定义
- 把从长度为T的压缩比特流 中decoded sequence记作
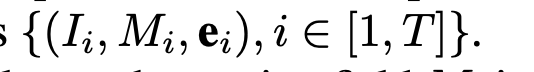
- 为了区分,用下标 i / k 来区分关键帧和非关键帧。对于非关键帧的,需要利用光流去做一次warp


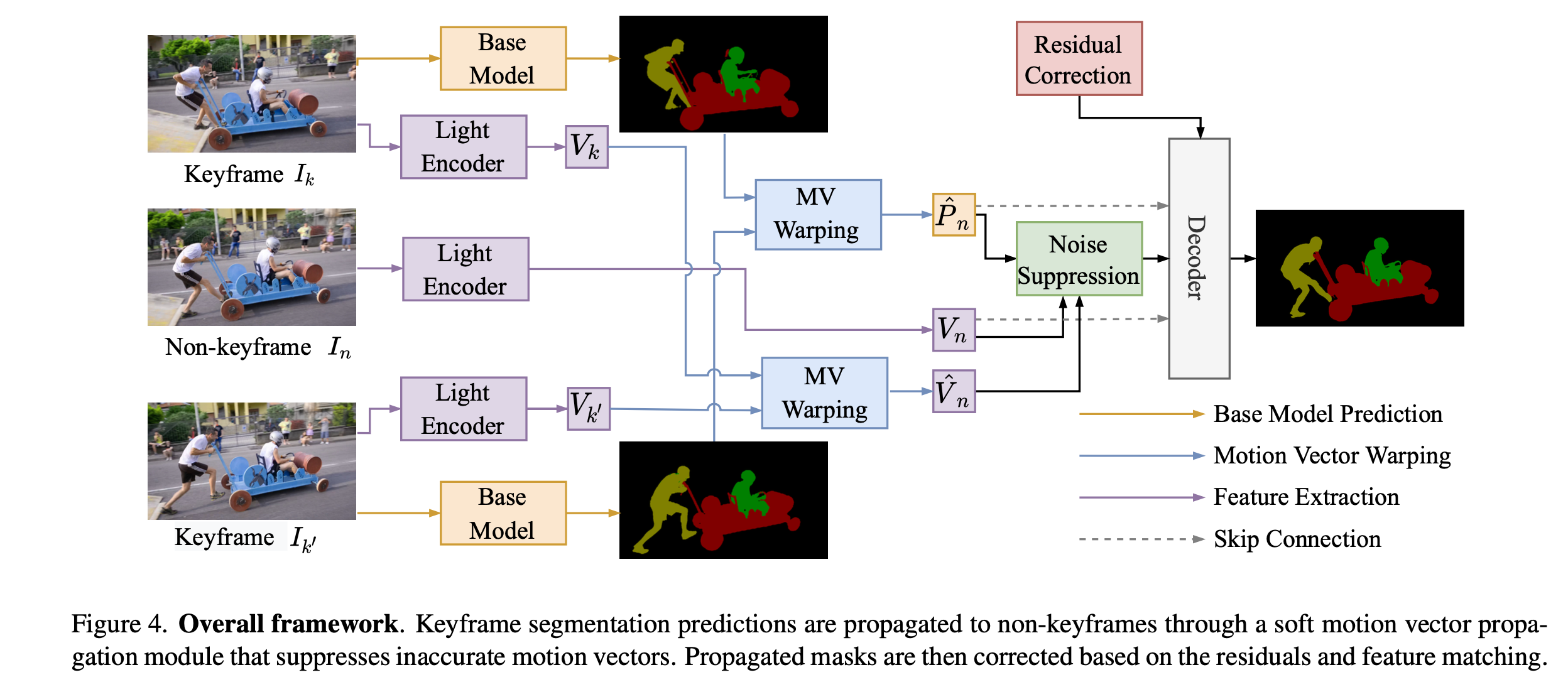
4.1 Soft motion-vector propagation module
- 介绍了如何用motion vector来替代光流。用P和V分别来表示segmentation 和 feature

- 前两个代表单向的propagation, 第三个表示双向的,前向和后向分别是等权重的。w表示重构目标中的tuning 参数。u,t为小数时,则对reference帧采用 最近邻 / 双线性插值。

- 为了消除noise / error的影响,用一个decoder 来实现soft 的 propagation。decoder是一个轻量级,对原始的mask进行denoise(参考image的low-level feature)

- 定义一个相似度来衡量propagate 前后的feature
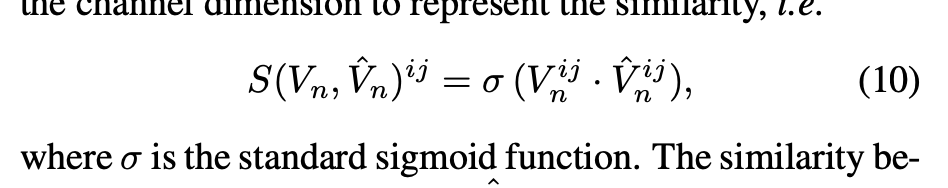
Residual-based correction module
- 通过patch generation 和 label matching来建模correction。 先把residue 转换成灰度空间,接着利用二值化得到binary mask。 把Residue 和 dilate后的前景mask 取交集,得到修正后的mask

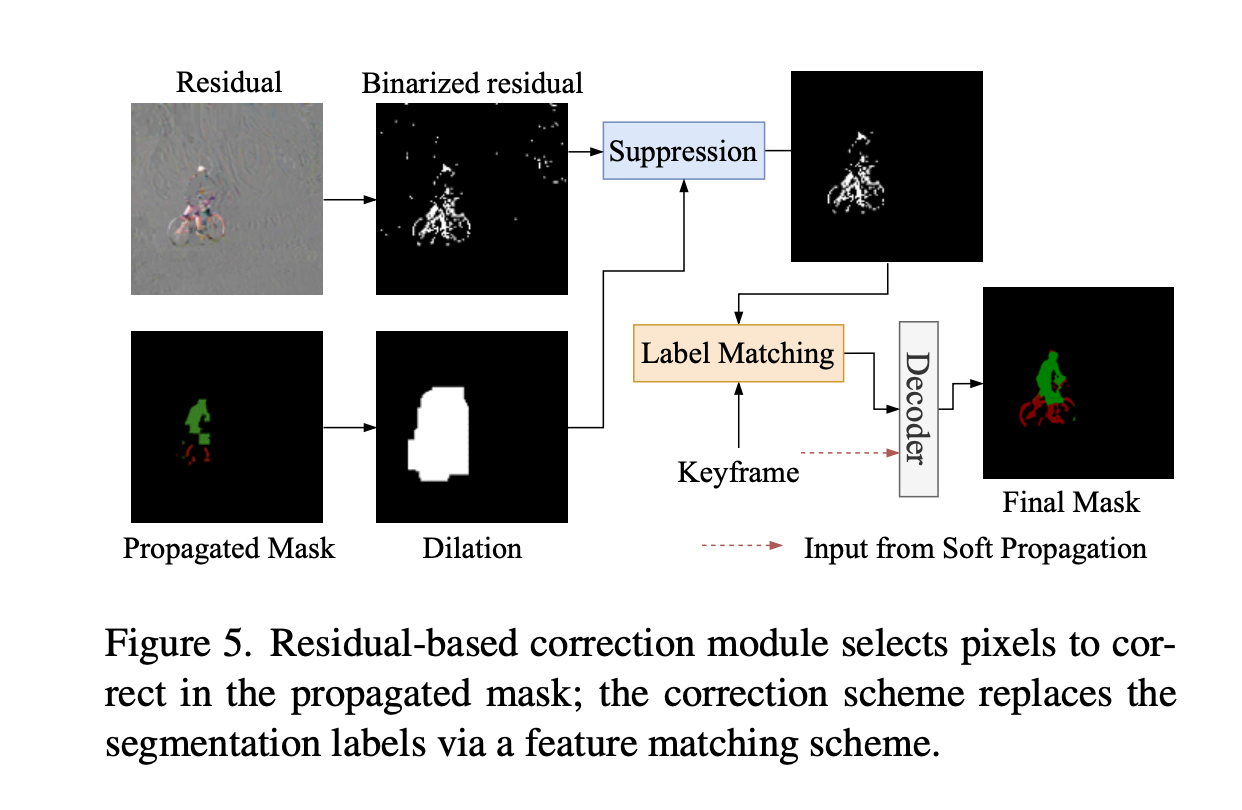
Key frame & base network selection
- 根据压缩类型来选择关键帧。关键帧不仅包括 I frame , 还包括 P frame。因为I frame的数量仅占到5%左右。P帧作为关键帧也可以提升精度,因为motion vector 在P帧中是严格单向的
- 采用memory network ,例如STM, MiVOS, and STCN比较适合加速